
计算DFT系数
计算DFT系数
提问于 2013-11-06 11:22:52
我有一个时间序列,它包含256个整数值。看起来是这样的:
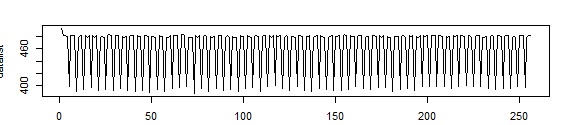
我计算了STFT(短时Forier变换),在r中计算了这段代码:
s<-stft(datalist, win=min(80,floor(length(datalist)/10)), inc=min(24,floor(length(datalist)/30)), coef=256, wtype="hanning.window")作为一个resault,我有一个29行256值的矩阵。如果我在一个图中显示这个矩阵的一行(即第10行)。我看到的是这样的一幅图:
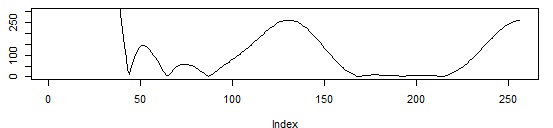
但我有这样的期望,即系数图应该看起来像第一个图表?(仅在另一个维度)。
我应该使用R中的另一个包来完成这项工作吗?还是我的理解是错误的?
回答 1
Stack Overflow用户
回答已采纳
发布于 2013-11-06 15:46:11
我想您正在使用来自stft的封装GENEArerad函数。在你的例子中,电话基本上是
s<-stft(datalist, win=25, inc=8, coef=256, wtype="hanning.window")所以我看它的方式,你拿了25个样本,但是计算了256个系数。文档指出,coef的最大(合理)值是win/2,这是由于我猜的奈奎斯特-香农抽样定理。因此,除前12个系数外,所有系数都是假的。前几个系数超出了你的地块的比例,所以我们也不能说这些。
我不知道你的期望从何而来,我也不分享。但我也相信,在你的期望中,还有一些更根本的问题要解决。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/19810788
复制相关文章
相似问题
腾讯云开发者
