
绘制按变量对分组的数据
绘制按变量对分组的数据
提问于 2013-12-13 16:13:18
我有大量这样的数据,由以下变量组成。
Field Country AgeRange Score Test我想把每一组按字段和AgeRange分组的人口的平均分数进行标出。那就是,我想要这样的东西。
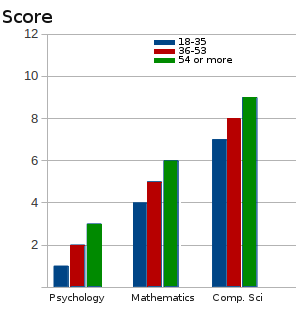
请注意,变量AgeRange接受这3个值中的一个,而不是每个参与者的确切年龄。
我没有问题,按需要分组数据。例如,通过
aggr_data = aggregate(data, by=list(data$Field, data$AgeRange), FUN=mean)我得到的数据分组的方式,我需要,与每个字段的得分平均值-年龄对。问题是,我找不到一种简单的方法,从y轴对应于所获得的分数,x轴对应于每对的值中得到一个条形图。
我想我可以抓住我感兴趣的每一个子集,就像这样
young_cs = subset(data, Field=="CompSci" & AgeRange=="18-35")
m_young_cs = mean(young_cs[,"Score"])
mid_cs = subset(data, Field=="CompSci" & AgeRange=="36-53")
m_mid_cs = mean(mid_cs[,"Score"])然后画出所有获得的手段,但这显然是非常耗时的。有没有更简单、更快的方法来做到这一点?
这是一个数据的随机小样本。
Field Country AgeRange Score Test
Psychology US 18-35 4.2 A
Psychology US 18-35 3.1 C
Psychology US 18-35 5.2 B
Psychology US 36-53 4.7 A
Psychology US 36-53 3.5 A
Psychology US 54+ 3.1 B
Psychology US 54+ 2.2 B
Psychology US 54+ 6.7 C
Psychology US 54+ 5.1 C
CompSci US 18-35 5.2 B
CompSci US 18-35 7.4 C
CompSci US 18-35 6.1 A
CompSci US 36-53 7.7 A
CompSci US 36-53 8.1 A
CompSci US 54+ 8.2 B
CompSci US 54+ 7.7 B
CompSci US 54+ 6.9 A
CompSci US 54+ 9.0 C
Mathematics US 18-35 6.2 B
Mathematics US 18-35 6.4 A
Mathematics US 18-35 7.1 A
Mathematics US 36-53 8.7 A
Mathematics US 36-53 9.4 A
Mathematics US 54+ 7.2 C
Mathematics US 54+ 6.1 B
Mathematics US 54+ 6.5 C
Mathematics US 54+ 7.0 C回答 2
Stack Overflow用户
回答已采纳
发布于 2013-12-13 17:19:20
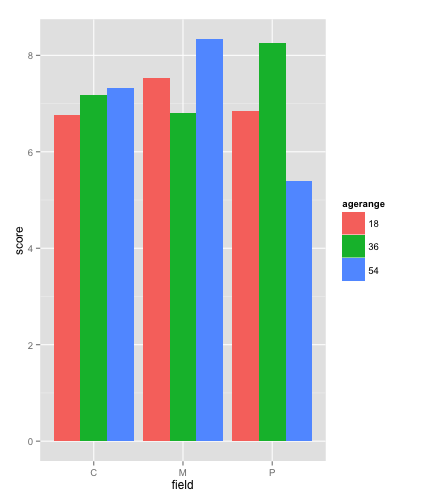
尝尝这个
#dummay data
field=c("P","C","M")
agerange=c(18,36,54)
score=rnorm(27, 7)
test=c("A","B","C")
df<-data.frame(field=rep(field, each=9),agerange= as.factor(rep(agerange,each=3, times=9)), score=score,test=rep(test, 9))
p<-ggplot(df, aes(x=field,y=score, fill=agerange))
p+geom_bar(stat="identity", position="dodge")
#or
p+stat_summary(fun.y = "mean",geom = "bar", position="dodge")
Stack Overflow用户
发布于 2013-12-13 17:23:24
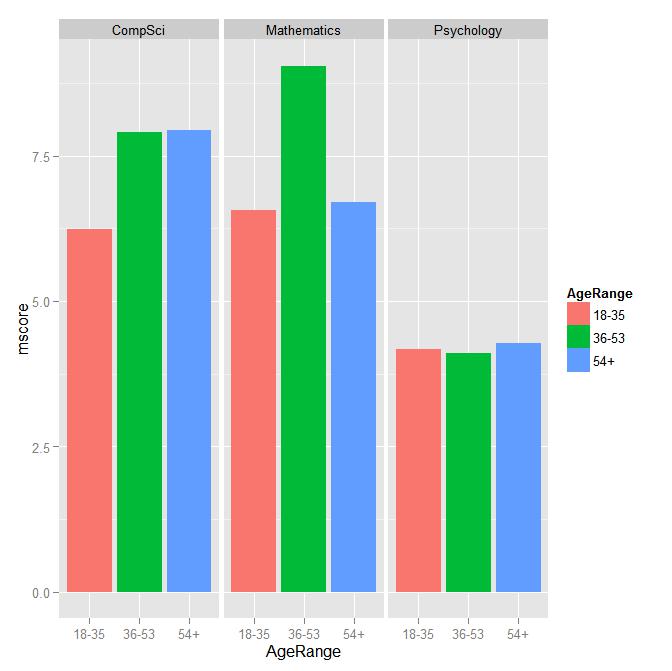
library(ggplot2)
library(plyr)
# a faceting approach
df2 <- ddply(df, .(Field, AgeRange), summarise, mscore = mean(Score))
ggplot(df2, aes(x=AgeRange, y = mscore, fill = AgeRange)) + geom_bar( stat = "identity" ) +
facet_wrap(~Field)
# good enough?
df <- structure(list(field = structure(c(3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), class = "factor", .Label = c("C",
"M", "P")), agerange = structure(c(1L, 1L, 1L, 2L, 2L, 2L, 3L,
3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L,
2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L,
2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L,
1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L,
3L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L), .Label = c("18", "36",
"54"), class = "factor"), score = c(7.30127138725929, 7.37770686922096,
7.41317998674043, 6.64841878521039, 7.86711279540953, 7.17048025193224,
8.44148594576163, 8.13949581473566, 6.30312423530373, 6.78529906805563,
8.60960304217661, 7.08300936020387, 7.33518750196135, 7.29903060579703,
7.81598828814603, 6.51481883845345, 6.85779851460457, 8.5001156704776,
7.90225168492658, 6.57536590278191, 6.01020914251986, 7.28458327350041,
7.07419918080273, 8.93252585403122, 6.54527682832174, 6.35152240141314,
6.75924970388344, 7.30127138725929, 7.37770686922096, 7.41317998674043,
6.64841878521039, 7.86711279540953, 7.17048025193224, 8.44148594576163,
8.13949581473566, 6.30312423530373, 6.78529906805563, 8.60960304217661,
7.08300936020387, 7.33518750196135, 7.29903060579703, 7.81598828814603,
6.51481883845345, 6.85779851460457, 8.5001156704776, 7.90225168492658,
6.57536590278191, 6.01020914251986, 7.28458327350041, 7.07419918080273,
8.93252585403122, 6.54527682832174, 6.35152240141314, 6.75924970388344,
7.30127138725929, 7.37770686922096, 7.41317998674043, 6.64841878521039,
7.86711279540953, 7.17048025193224, 8.44148594576163, 8.13949581473566,
6.30312423530373, 6.78529906805563, 8.60960304217661, 7.08300936020387,
7.33518750196135, 7.29903060579703, 7.81598828814603, 6.51481883845345,
6.85779851460457, 8.5001156704776, 7.90225168492658, 6.57536590278191,
6.01020914251986, 7.28458327350041, 7.07419918080273, 8.93252585403122,
6.54527682832174, 6.35152240141314, 6.75924970388344), test = structure(c(1L,
2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L,
3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L,
1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L,
2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L,
3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L
), class = "factor", .Label = c("A", "B", "C"))), .Names = c("field",
"agerange", "score", "test"), row.names = c(NA, -81L), class = "data.frame")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/20570975
复制相关文章
相似问题
腾讯云开发者
