
删除假逗号
一个白痴客户正在生成csv文件,但是一个字段有时在(描述字段)中有额外的逗号。
是否有一个整齐的正则表达式来查找这些坏记录,并用其他东西替换额外的逗号。SED命令行就行了。
示例:
A,B,C,This is a description,D,E
F,G,H,This is a description with a comma (,) in it,D,E我需要一个SED,可以判断有太多的逗号在行和删除额外的逗号从字段4。
我们没有权利告诉愚蠢的客户更改他们的代码。
添加了
我不反对只删除、一个伪逗号而不得不多次运行的解决方案。
回答 4
Stack Overflow用户
发布于 2014-01-22 10:40:50
解决方案1:单行删除,
这是一个SED单线线:
sed -r 's/([^,],[^,],[^,],)(.*)(,.+,.+)/\1'"$(sed -r 's/([^,],[^,],[^,],)(.*)(,.+,.+)/\2/' <<< $myInput | sed 's/,//g')"'\3/' <<< $myInput无论实际输入是什么,您都必须替换<<< $myInput。
当您使用CSV时,您可能必须调整(两者都发生)正则表达式,以便在CSV表的每一行上匹配。
如果前三个和最后两个字段大于一个字符,则将[^,]替换为[^,]*。
解释
我们用这个正则表达式
/([^,],[^,],[^,],)(.*)(,.+,.+)/它为我们捕获字符串的第一部分(F,G,H,)、第二部分(.*)和最后一部分(,D,E)。
第一和第三捕获组将保持不变,而第二捕获组将被替换。
对于替换,我们称sed为第二次(实际上是第三次)时间。首先,我们只捕获第二个组,其次,我们用任何东西替换每个, (只在捕获组中!)。
证明:

当然,如果没有不需要的逗号,则不会替换任何内容:

解决方案2:如果您只想指定一个文件**一个文件**,那么整个文件、逐行删除, ##,并且您可以使用的文件的每一行都应该进行替换。
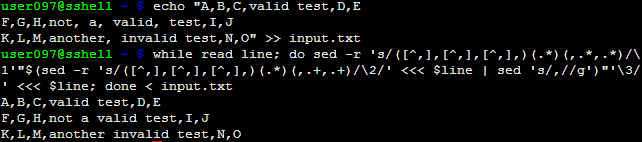
while read line; do sed -r 's/([^,],[^,],[^,],)(.*)(,.+,.+)/\1'"$(sed -r 's/([^,],[^,],[^,],)(.*)(,.+,.+)/\2/' <<< $line | sed 's/,//g')"'\3/' <<< $line; done < input.txt最后的input.txt是-显然-你的文件。
我只是在上面的while-loop中使用SED-命令,它读取文本的每一行。这是必要的,因为您必须跟踪正在读取的行,因为您在相同的输入上调用sed两次。
解决方案3:整个文件,将" ##中的字段括起来,正如@Łukasz L.在OP的注释中指出的那样,根据描述CSV格式的RFC1480 -文件,最好将包含逗号的字段括在"中。这比其他解决方案更简单:
sed -r 's/([^,],[^,],[^,],)(.*)(,.*,.*)/\1"\2"\3/' input.txt再一次,我们有三个捕获组。这样我们就可以简单地在"中包装第二个组了!

Stack Overflow用户
发布于 2014-01-22 10:53:25
如果列计数是固定的,我们可以尝试用?:裁剪前三列和最后两列,并在行的其余部分(这是描述)中匹配逗号。我有这样的东西:
(?:^(?:[^,]*,){3})(?:(?:[^,]*(,))*[^,]*)(?:(?:,[^,]*){2}$)[^,]*是字段(没有逗号),因此(?:^(?:[^,]*,){3})将剪切前3列(包括以下逗号)。(?:(?:,[^,]*){2}$)将删除最后2列,包括后缀逗号。(?:(?:[^,]*(,))*[^,]*)与内部匹配。
在JavaScript中,整个表达式返回完整的描述(用逗号)作为第一个匹配,其中的命令作为第二个。它提供了一种可能性,取决于Regex,要么使用espace替换描述(如果引擎给出匹配表达式的范围),要么用替换语法将匹配逗号的(,)表达式作为目标。
我现在没有使用sed运行和测试的可能性,但是这个正则表达式应该非常接近您需要的解决方案。
Stack Overflow用户
发布于 2014-01-21 22:14:10
我试图用sed解决这个问题,但是无法在匹配组中执行替换。相反,我成功地使用了一个可以从终端运行的红宝石单衬垫:
cat your_file | ruby -ne '$_.scan(/^(\w+,\w+,\w+,)([^$]+)(,\w,\w)$/).each{|m|puts m[0]+m[1].gsub(",","")+m[2]}'这假设总是有6列,第4列可能包含逗号。
代码已经用ruby1.8.7、1.9.1和2.1.0进行了测试。
https://stackoverflow.com/questions/21265304
复制相似问题
腾讯云开发者
