
在Spark0.9.0抛出错误上运行作业
在Spark0.9.0抛出错误上运行作业
提问于 2014-02-10 12:23:17
我已经安装了一个ApacheSpark0.9.0集群,在这里我试图部署一个从HDFS读取文件的代码。这段代码抛出一个警告,最终作业失败。这是代码
/**
* running the code would fail
* with a warning
* Initial job has not accepted any resources; check your cluster UI to ensure that
* workers are registered and have sufficient memory
*/
object Main extends App {
val sconf = new SparkConf()
.setMaster("spark://labscs1:7077")
.setAppName("spark scala")
val sctx = new SparkContext(sconf)
sctx.parallelize(1 to 100).count
}下面是警告消息
初始作业未接受任何资源;请检查群集用户界面,以确保工作人员已注册并拥有足够的内存。
如何摆脱这个或我错过了一些配置。
回答 7
Stack Overflow用户
发布于 2014-03-23 11:50:47
当通过设置spark.cores.max和spark.executor.memory resp‘请求的核心数量或内存数量(每个节点)超过可用时,您就会得到这个结果。因此,即使没有其他人使用集群,并且您指定要使用,假设每个节点使用100 get,但是节点只能支持90 get,那么您将收到此错误消息。
公平地说,在这种情况下,这个信息是模糊的,如果它说你超过了最大值会更有帮助。
Stack Overflow用户
发布于 2014-02-11 08:13:18
看来火花公子主人不能为这个任务指派任何工人。要么工人没有开始工作,要么他们都很忙。
检查主节点上的Spark (默认情况下由SPARK_MASTER_WEBUI_PORT在spark-env.sh中指定端口,8080 )。它应该是这样的:
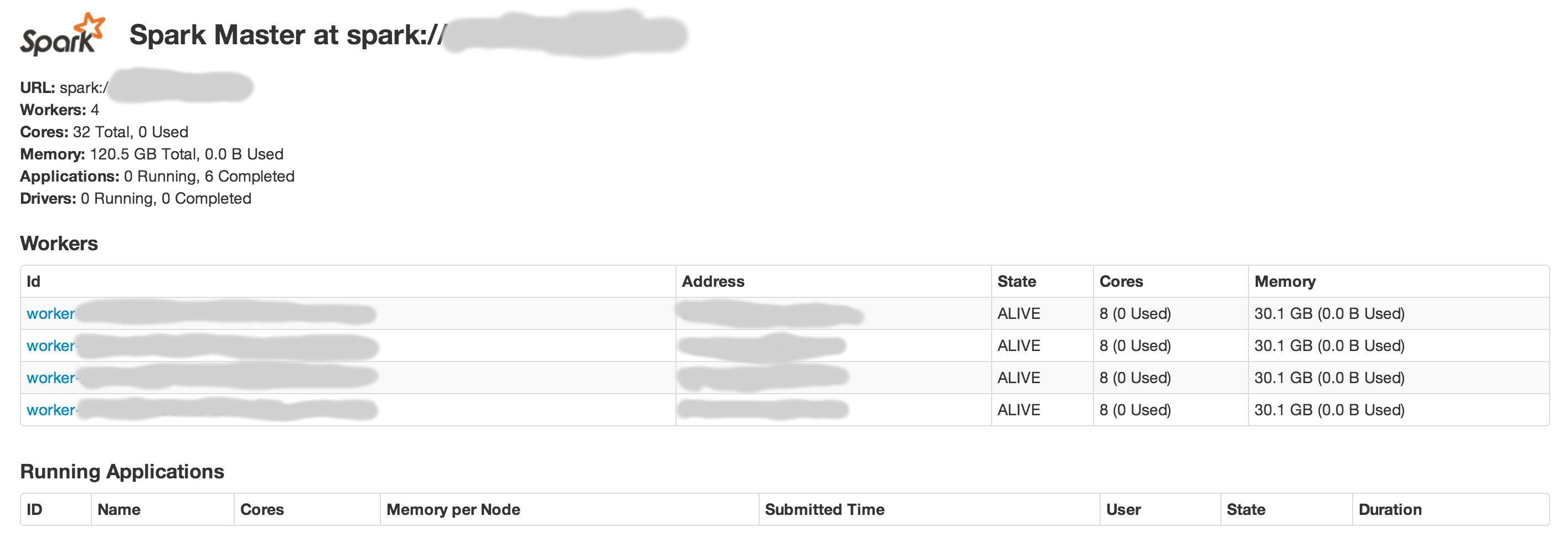
为使集群正常运作:
- 一定有一些国家“活着”的工人
- 必须有一些可用的核心(例如,如果所有核心都忙于冻结的任务,集群将不接受新任务)
- 必须有足够的内存可用
Stack Overflow用户
发布于 2014-03-24 18:52:04
另外,确保你的火花工作人员可以与司机进行双向交流。检查防火墙等。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/21677142
复制相关文章
相似问题
腾讯云开发者
