
反别名文本的OCR
反别名文本的OCR
提问于 2014-02-17 11:28:40
我必须从PDF文档中提取OCR表。我编写了简单的Python+opencv脚本来获取单个单元格。在那个新问题出现之后。文本是反别名的,而且质量不好。的识别率很低。我试着用自适应阈值对图像进行预处理,但效果并不好。我尝试过ABBYY FineReader的试用版,实际上它提供了很好的输出,但我不想使用非免费软件。我想知道某些预处理是否能解决问题,或者编写和学习其他OCR系统是否必要。

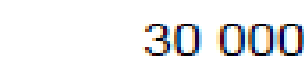
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-02-17 14:18:00
如果您仔细查看您的反别名文本示例,您会注意到边缘包含大量的红色和蓝色:
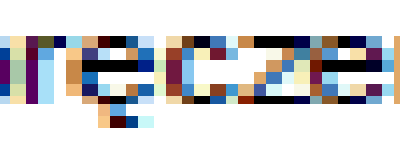
这表明,反混叠发生在您的计算机内,它使用亚像素渲染来优化您的液晶显示器的结果。
如果是这样的话,应该很容易以较高的分辨率提取文本。例如,可以使用ImageMagick从300 dpi的PDF文件中提取图像,方法是使用命令行,如下所示:
convert -density 300 source.pdf output.png您甚至可以尝试将PDF加载到您最喜欢的查看器中,并将文本直接复制到剪贴板。
增编:
我尝试将示例文本转换回原始像素,并应用注释中提到的缩放技术。以下是研究结果:
原始图像:

在缩放300%并应用简单阈值之后:

在智能缩放和阈值处理之后:

正如你所看到的,有些字母仍然有一些不正确的形式,但我认为用Tesseract阅读这篇文章的可能性更大。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/21827854
复制相关文章
相似问题
腾讯云开发者
