
熊猫长到宽的形状,由两个变量组成
熊猫长到宽的形状,由两个变量组成
提问于 2014-04-01 23:37:44
我有长格式的数据,并试图将数据整形为wide,但似乎没有一种直接的方法可以使用熔体/堆栈/未堆栈:
Salesman Height product price
Knut 6 bat 5
Knut 6 ball 1
Knut 6 wand 3
Steve 5 pen 2变成:
Salesman Height product_1 price_1 product_2 price_2 product_3 price_3
Knut 6 bat 5 ball 1 wand 3
Steve 5 pen 2 NA NA NA NA我认为Stata可以用reshape命令来做这样的事情。
回答 6
Stack Overflow用户
回答已采纳
发布于 2014-04-02 01:30:23
一个简单的枢轴可能足以满足您的需求,但这就是我为再现您想要的输出所做的工作:
df['idx'] = df.groupby('Salesman').cumcount()仅仅添加一个组内计数器/索引就可以使您在大多数情况下达到目的,但是列标签将不像您想要的那样:
print df.pivot(index='Salesman',columns='idx')[['product','price']]
product price
idx 0 1 2 0 1 2
Salesman
Knut bat ball wand 5 1 3
Steve pen NaN NaN 2 NaN NaN为了更接近您想要的输出,我添加了以下内容:
df['prod_idx'] = 'product_' + df.idx.astype(str)
df['prc_idx'] = 'price_' + df.idx.astype(str)
product = df.pivot(index='Salesman',columns='prod_idx',values='product')
prc = df.pivot(index='Salesman',columns='prc_idx',values='price')
reshape = pd.concat([product,prc],axis=1)
reshape['Height'] = df.set_index('Salesman')['Height'].drop_duplicates()
print reshape
product_0 product_1 product_2 price_0 price_1 price_2 Height
Salesman
Knut bat ball wand 5 1 3 6
Steve pen NaN NaN 2 NaN NaN 5编辑:如果你想把这个过程推广到更多的变量,我认为你可以做如下的事情(尽管它可能不够有效):
df['idx'] = df.groupby('Salesman').cumcount()
tmp = []
for var in ['product','price']:
df['tmp_idx'] = var + '_' + df.idx.astype(str)
tmp.append(df.pivot(index='Salesman',columns='tmp_idx',values=var))
reshape = pd.concat(tmp,axis=1)@卢克说: 我认为Stata可以用reshape命令来做这样的事情。
您可以,但我认为您还需要一个组内计数器来获得stata中的整形以获得您想要的输出:
+-------------------------------------------+
| salesman idx height product price |
|-------------------------------------------|
1. | Knut 0 6 bat 5 |
2. | Knut 1 6 ball 1 |
3. | Knut 2 6 wand 3 |
4. | Steve 0 5 pen 2 |
+-------------------------------------------+如果添加idx,则可以在stata中进行整形
reshape wide product price, i(salesman) j(idx)Stack Overflow用户
发布于 2016-07-20 22:50:32
下面是另一个更充实的解决方案,取自克里斯·阿尔本网站。
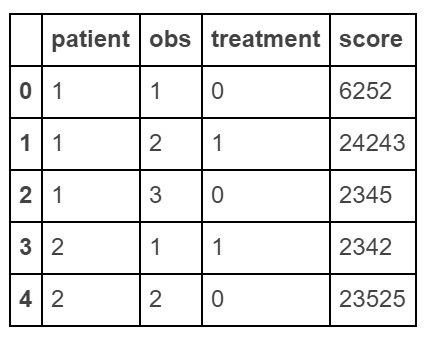
创建“长”数据
raw_data = {'patient': [1, 1, 1, 2, 2],
'obs': [1, 2, 3, 1, 2],
'treatment': [0, 1, 0, 1, 0],
'score': [6252, 24243, 2345, 2342, 23525]}
df = pd.DataFrame(raw_data, columns = ['patient', 'obs', 'treatment', 'score'])
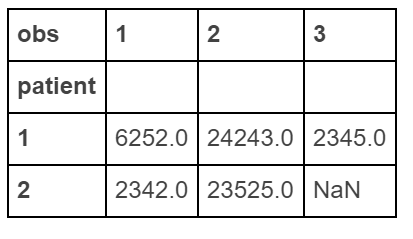
做一个“宽”数据
df.pivot(index='patient', columns='obs', values='score')
Stack Overflow用户
发布于 2019-03-20 01:47:55
卡尔·D的解决方案是问题的核心。但是,我发现更容易的方法是将所有内容(使用.pivot_table,因为有两个索引列),然后sort和分配列来折叠MultiIndex
df['idx'] = df.groupby('Salesman').cumcount()+1
df = df.pivot_table(index=['Salesman', 'Height'], columns='idx',
values=['product', 'price'], aggfunc='first')
df = df.sort_index(axis=1, level=1)
df.columns = [f'{x}_{y}' for x,y in df.columns]
df = df.reset_index()输出:
Salesman Height price_1 product_1 price_2 product_2 price_3 product_3
0 Knut 6 5.0 bat 1.0 ball 3.0 wand
1 Steve 5 2.0 pen NaN NaN NaN NaN页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/22798934
复制相关文章
相似问题
腾讯云开发者
