
批量查找ES瓶颈(附大屏幕截图)
更新:小心长帖
在我转到更大的服务器之前,我想了解一下这个服务器有什么问题。
这是AWS (EC2)中elasticsearch服务器的MVP。两台微型,每台只有600 ram的内存。
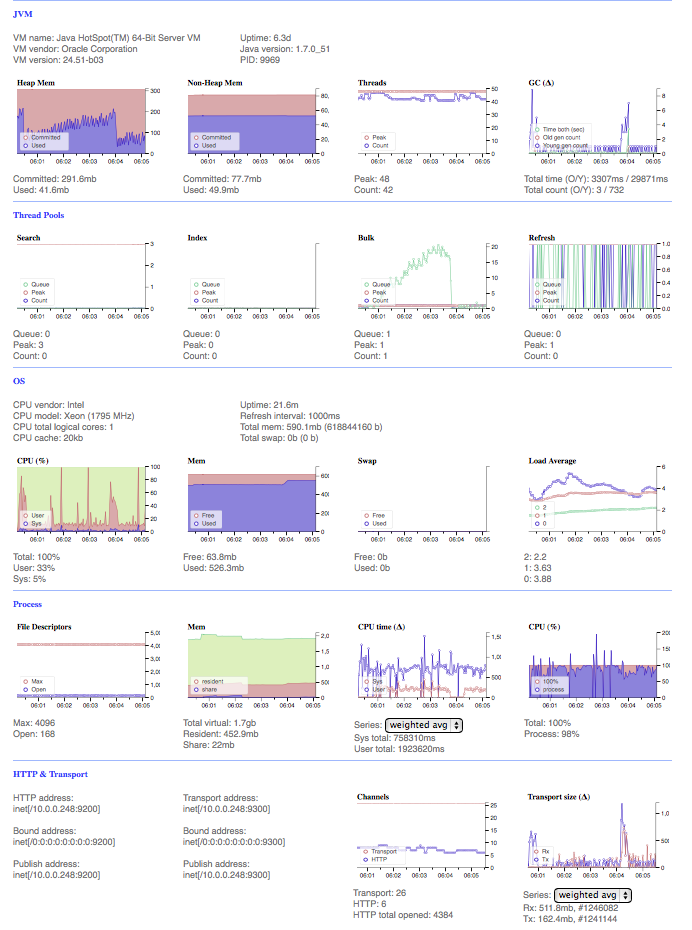
我想知道这个配置有什么问题。如您所见,bulk命令有一个瓶颈。OS内存相当满,堆内存仍然很低,虽然进程CPU最大运行,但OS cpu很低。
我降低了批量提要中每个文档的复杂性,并将不想要的字段设置为没有索引。下面的截图是我最后一次尝试。
这是I/O瓶颈吗?我将数据存储在一个S3桶上。
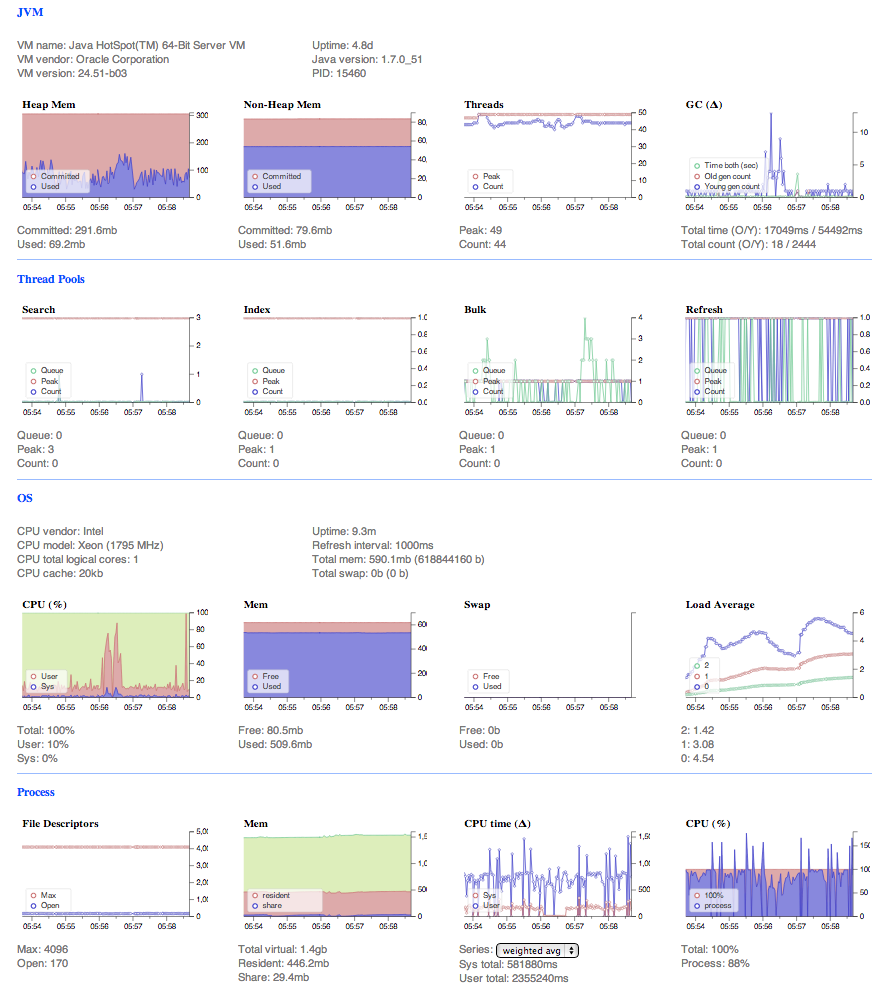
服务器信息:
两个节点(每个服务器一个),三个索引,每个节点运行两个碎片和一个副本。所以它是一个主节点,它有一个正在运行的备份节点。奇怪的是,“铁人”节点从未接管过碎片。

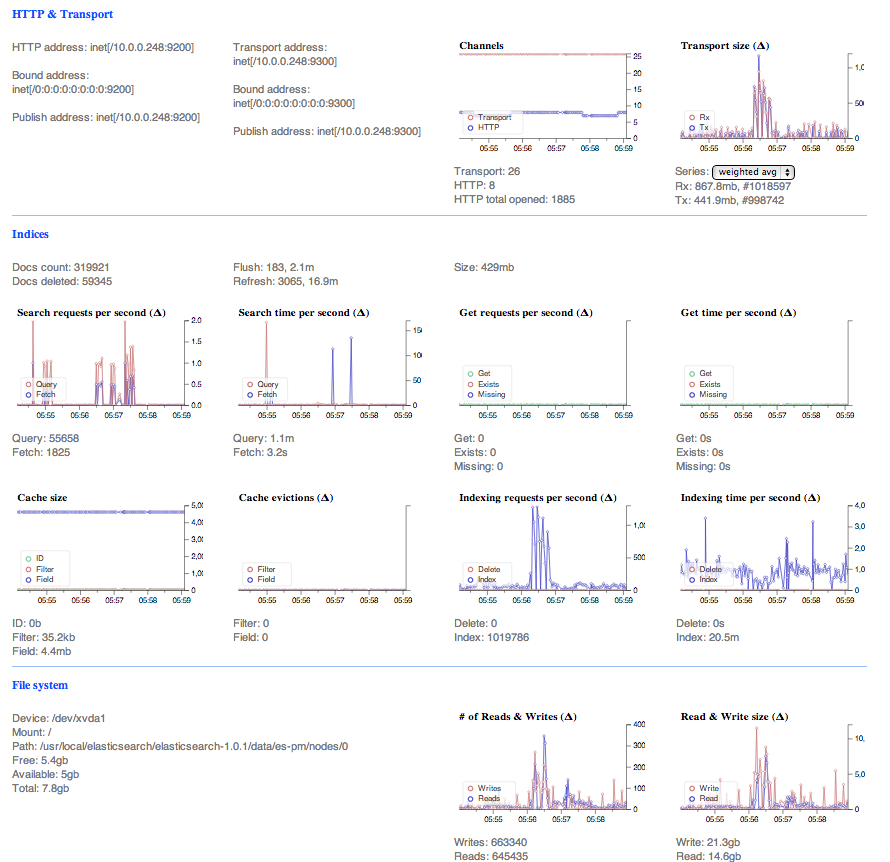
我再次运行具有上述群集状态的馈线,瓶颈似乎出现在两个节点上:
这里是馈线的开始:
初级
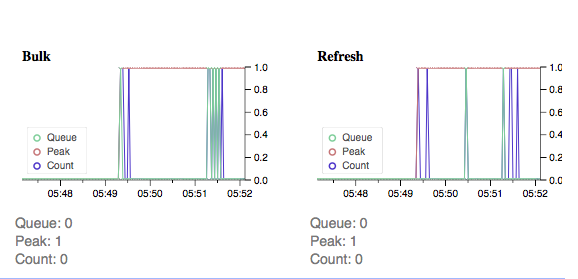
二级(二级有瓶颈):

喂食5分钟后:
主(现在主要存在瓶颈)
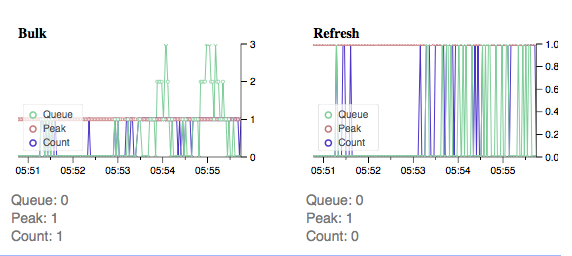
中学(现在中学更好):
我使用py-elasticsearch,所以请求在流光中自动节流。然而,在它下面的大瓶颈抛出了这个错误之后:
elasticsearch.exceptions.ConnectionError:
ConnectionError(HTTPConnectionPool(host='IP_HERE', port=9200):
Read timed out. (read timeout=10)) caused by:
ReadTimeoutError(HTTPConnectionPool(host='IP_HERE', port=9200):
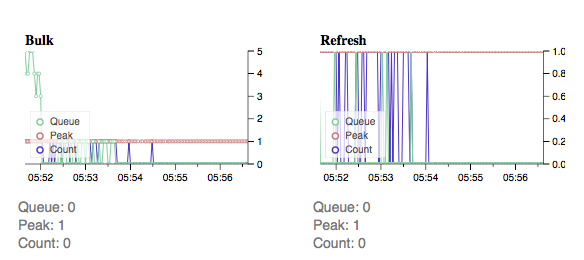
Read timed out. (read timeout=10))下面是一个非常有趣的截图,在同样的“散装饲料”。队列达到20,python将表达式抛到上面,refresh命令在我编写之前运行。
我的目标是了解哪个源(CPU、RAM、磁盘、网络)。是更有效地利用现有资源的不足甚至更好。
回答 2
Stack Overflow用户
发布于 2014-04-10 17:10:01
您能对批量索引的索引运行IndexPerfES.sh脚本吗?然后我们可以查看性能是否有所提高。我认为刷新速率降低了性能,可能会对集群造成压力,从而导致问题。告诉我,我们可以解决这个问题。
Stack Overflow用户
发布于 2014-04-11 12:11:09
因此,Nate的脚本(以及其他脚本)缩短了刷新间隔。我还要补充一些其他的调查结果:
刷新速率使集群更加紧张,但是我继续搜索,发现了更多的“错误”。其中一个问题是我有一个不推荐的S3.Gateway。S3是持久的,但比EC2卷慢。
我不仅有S3作为数据存储,而且在不同的区域(ec2、virginia、->、s3、俄勒冈州)。所以通过网络发送文件。我之所以谈到这一点,是因为一些老教程将S3作为云数据存储选项。
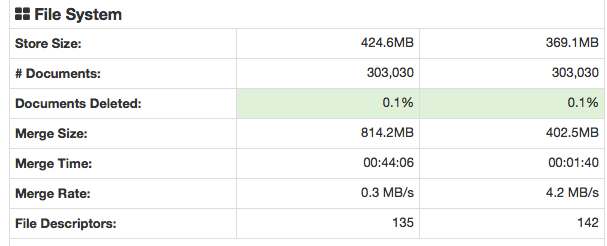
解决这一问题后,下文所删除的“文件”更好。当我使用S3的时候,它大约是30%。这是Elasticsearch的HQ插件。
从现在开始,我们已经优化了I/O。让我们看看还能做些什么。
我发现CPU是个问题。虽然大办公桌说工作量很小,但t1.micros是不用于持久的CPU使用。这意味着,虽然在图表上,CPU没有被充分使用,但这是因为Amazon在时间间隔和实际使用时间上限制了CPU的使用。
如果您放置一个更大更复杂的文档,它将对服务器造成压力。
进展愉快。
https://stackoverflow.com/questions/22802547
复制相似问题
腾讯云开发者
