
如何设置非ANSI字符的蟒蛇大熊猫的排列方式
如何设置非ANSI字符的蟒蛇大熊猫的排列方式
提问于 2014-04-11 09:26:49
当我以R格式读取数据( M370空难中的死亡)时,格式很好。
> read.csv("g:\\test.ansi",sep=",")
乘客姓名 性别 出生日期
1 HuangTianhui 男 1948/05/28
2 姜翠云 女 1952/03/27
3 李红晶 女 1994/12/09
4 LuiChing 女 1969/08/02
5 宋飞飞 男 1982/03/01
6 唐旭东 男 1983/08/03
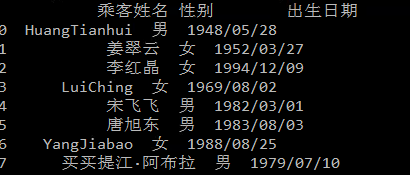
7 YangJiabao 女 1988/08/25当我阅读python中的数据时,如何才能正确地设置记录对齐方式?
>>> import pandas as pd
>>> pd.read_csv("g:\\test.ansi",sep=",")
乘客姓名 性别 出生日期
0 HuangTianhui 男 1948/05/28
1 姜翠云 女 1952/03/27
2 李红晶 女 1994/12/09
3 LuiChing 女 1969/08/02
4 宋飞飞 男 1982/03/01
5 唐旭东 男 1983/08/03
6 YangJiabao 女 1988/08/25
7 买买提江·阿布拉 男 1979/07/10数据在这里:http://pan.baidu.com/s/1sjHauL3
回答 2
Stack Overflow用户
回答已采纳
发布于 2014-04-11 16:37:45
原因是在处理汉字(占用两个ANSI字符的空间)时,pandas仍然填充ANSI字符的空白。这意味着空白的数量仅为包含汉字的DF所需的一半。更糟糕的是,pandas忽略了汉字占用了两倍的空间:
print pd.read_csv("test.ansi",sep=",", encoding='gb18030').loc[10:12]
10 边亮京 男 1987/06/06
11 边茂勤 女 1947/07/19
12 曹蕊 女 1982/02/19
#notice how the last line is missing one leading white space compared to the preceding lines.最后,所有这些都归结为DataFrame类的DataFrame类,该类根据_repr_fit_horizontal_类分配空间。我不知道什么是最好的解决办法。当遇到汉字时,用两个空格代替一个空格?在混合行的情况下,这不是一个好主意,有些行有汉字,有些行没有汉字,比如在这个dataframe中。
也许值得把这件事报告为一个bug。
但是,如果使用IPython笔记本,则受此问题影响较小,因为DataFrames很好地显示为HTML。
Stack Overflow用户
发布于 2019-12-03 09:54:46
我也遇到过这个问题。在查看了dataframe的呈现代码之后,我在熊猫源代码(v0.25)中找到了以下方法:
def _get_adjustment():
use_east_asian_width = get_option("display.unicode.east_asian_width")
if use_east_asian_width:
return EastAsianTextAdjustment()
else:
return TextAdjustment()因此,解决方案是在打印包含CJK字符的数据文件之前设置该选项。
import pandas as pd
your_df = pd.read_csv('some_path.txt') # load data into dataframe
pd.set_option("display.unicode.east_asian_width", True)
print(your_df)将它应用于您的数据之后,它就可以工作了。

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23008636
复制相关文章
相似问题
腾讯云开发者
