
Kinect是如何计算深度的?
Kinect是如何计算深度的?
提问于 2014-04-11 16:46:21
我有点糊涂了。
如何计算深度:我所理解的是
- 红外投影仪抛出一个模式,该模式被反射回来,并由红外摄像机读取。
- 现在红外相机知道特定深度的图案。利用传入模式和已知模式之间的差异来计算使用三角剖分(使用类似三角形的比例性)所知的深度。
问题1:它考虑了红外投影仪和红外摄像机之间的距离吗?我想没有,因为它们太近了,不值得考虑。
问题2,:现在我们直接从模式中获得深度。我们什么时候用disparity map计算深度?
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-04-12 04:58:40
视差图基本上是你一开始提到的已知和观察到的模式之间的区别。在深度计算过程中使用此方法。
投影仪和照相机之间的距离也会被考虑在内。
请查看以下数字:
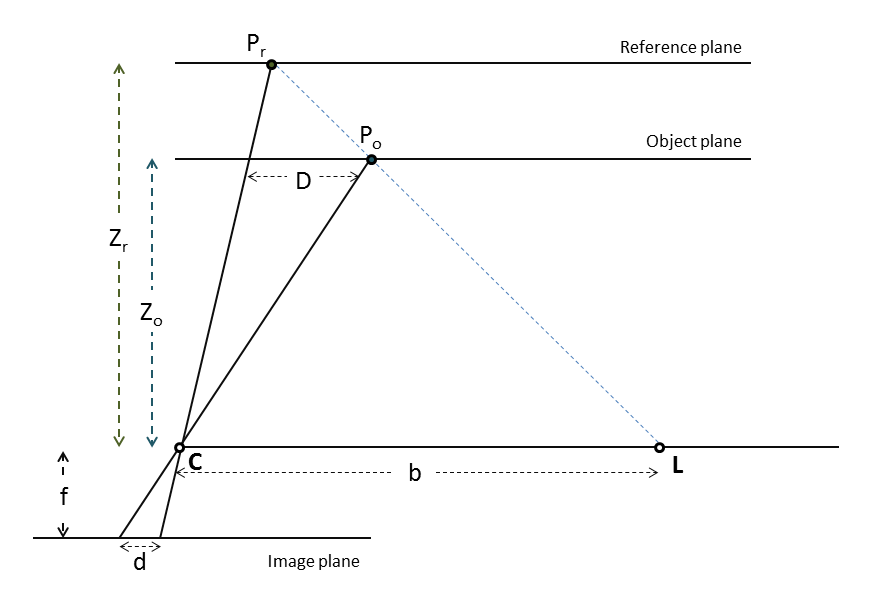
Pr是参考深度Zr中散斑的位置,Po是由Kinect在深度Zo (我们想要计算的深度)捕获的相同的散斑。D是两点之间的三维视差,d是二维图像平面上的视差。f是焦距,b是摄像机C与激光投影仪L之间的距离。
正如您所提到的,使用类似的三角形计算深度如下:
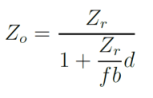
这个数字来自的文件是K.霍谢勒姆的动态深度数据的精度分析。我建议阅读它,以便更彻底地解释深度计算过程。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23018233
复制相关文章
相似问题
腾讯云开发者
