
R中列表中字符串的合并向量
我有一组字符串和ID中的相应ID:string格式作为R中的向量列表
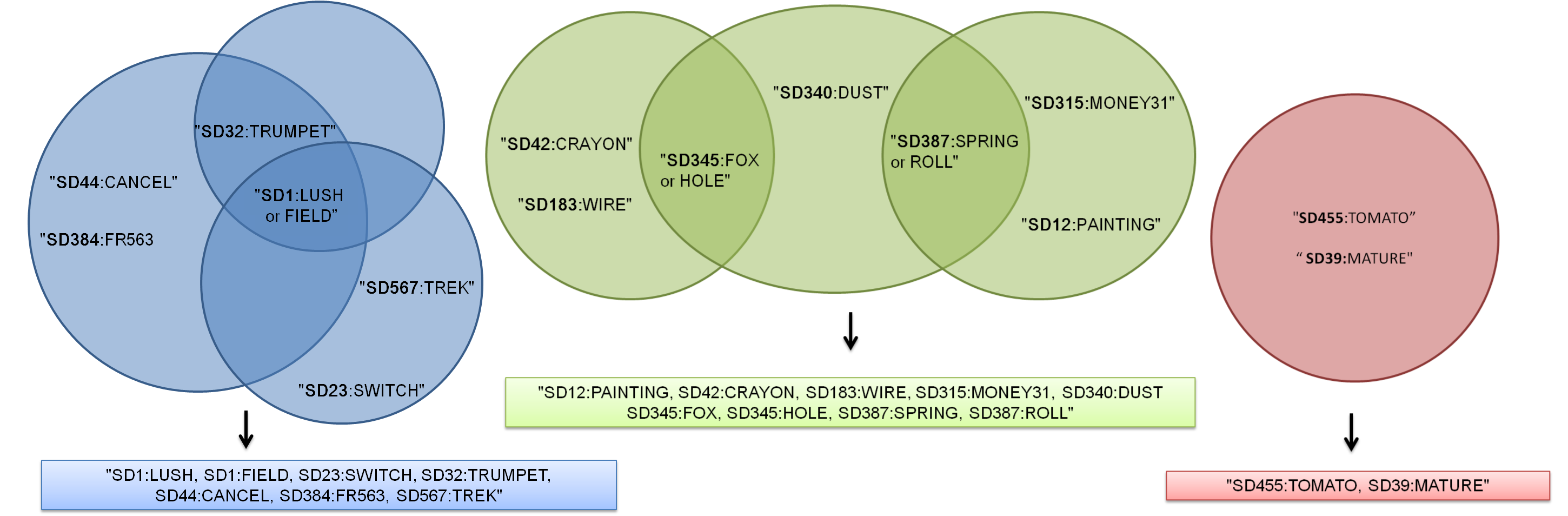
d <- list( c("SD1:LUSH", "SD44:CANCEL", "SD384:FR563", "SD32:TRUMPET"), c("SD23:SWITCH", "SD1:LUSH", "SD567:TREK"), c("SD42:CRAYON", "SD345:FOX", "SD183:WIRE"), c("SD345:HOLE", "SD340:DUST", "SD387:ROLL"), c("SD455:TOMATO", "SD39:MATURE"), c("SD12:PAINTING", "SD315:MONEY31", "SD387:SPRING"), c("SD32:TRUMPET", "SD1:FIELD"))
[[1]]
[1] "SD1:LUSH" "SD44:CANCEL" "SD384:FR563" "SD32:TRUMPET"
[[2]]
[2] "SD23:SWITCH" "SD1:LUSH" "SD567:TREK"
[[3]]
[3] "SD42:CRAYON" "SD345:FOX" "SD183:WIRE"
[[4]]
[4] "SD345:HOLE" "SD340:DUST" "SD387:ROLL"
[[5]]
[5] "SD455:TOMATO" "SD39:MATURE"
[[6]]
[6] "SD12:PAINTING" "SD315:MONEY31" "SD387:SPRING"
[[7]]
[7] "SD32:TRUMPET" "SD1:FIELD" 我想通过它们的ID将向量合并。具有公共ID的向量需要合并,同时保持对应的字符串以形成新的向量。重复ID:可以在合并的字符串中删除字符串组合。总数据包含了大约2000种这种载体。样例数据的期望输出是
out <- c("SD1:LUSH, SD1:FIELD, SD23:SWITCH, SD32:TRUMPET, SD44:CANCEL, SD384:FR563, SD567:TREK", "SD12:PAINTING, SD42:CRAYON, SD183:WIRE, SD340:DUST SD345:FOX, SD345:HOLE, SD387:SPRING, SD387:ROLL", "SD455:TOMATO, SD39:MATURE")
[1] "SD1:LUSH, SD1:FIELD, SD23:SWITCH, SD32:TRUMPET, SD44:CANCEL, SD384:FR563, SD567:TREK"
[2] "SD12:PAINTING, SD42:CRAYON, SD183:WIRE, SD315:MONEY31, SD340:DUST SD345:FOX, SD345:HOLE, SD387:SPRING, SD387:ROLL"
[3] "SD455:TOMATO, SD39:MATURE"我尝试过将其转换为data.frame来使用merge(),但发现它并不有用。是否可以首先使用字符串的ID部分搜索交集,然后将相应的向量合并。我尝试过使用intersect()和union(),但是我不能只使用向量的ID部分。
我对写R脚本相当陌生。
正如@CarlWitthoft所指出的,Update试图使与此图像合并的匹配条件更加清晰。
简而言之,我想要合并在它们之间有一个交集的向量的SDxyz:___,或者试图得到重叠的字符串向量的联合。
解决了!!
回答 3
Stack Overflow用户
发布于 2014-05-07 12:05:44
创建一个data.table块,其中一个列包含原始组,另一个列包含分隔的ids
d <- list( c("SD1:LUSH", "SD44:CANCEL", "SD384:FR563", "SD32:TRUMPET"), c("SD23:SWITCH", "SD1:LUSH", "SD567:TREK"), c("SD42:CRAYON", "SD345:FOX", "SD183:WIRE"), c("SD345:HOLE", "SD340:DUST", "SD387:ROLL"), c("SD455:TOMATO", "SD39:MATURE"), c("SD12:PAINTING", "SD315:MONEY31", "SD387:SPRING"), c("SD32:TRUMPET", "SD1:FIELD"))
d2 <- lapply(d, function(x) sapply(strsplit(x, ":"), "[", 1))
d <- lapply(d, paste0, collapse=", ")
d2 <- lapply(d2, paste0, collapse=", ")
d <- as.data.frame(as.matrix(lapply(d, paste0, collapse=", ")))
d2 <- as.data.frame(as.matrix(lapply(d2, paste0, collapse=", ")))
d <- as.data.frame(cbind(d,d2))
colnames(d) <- c("sdw", "sd")
d$sd <- as.character(d$sd)
d$sdw <- as.character(d$sdw)
require(data.table)
Bloc <- data.table( d , key = "sd" )在Bloc中获取所有in以及相应的数据。
Bloc <- Bloc[ , list( ID = unlist( strsplit( sd , "," ) ) ) , by = list(sdw, sd) ]
Bloc$ID <- gsub("^\\s+|\\s+$", "", Bloc$ID)
Bloc <- data.table( Bloc , key = "ID" )循环,以合并在它们之间有ids相交的向量。
Bloc <- as.data.frame(Bloc)
M <- nrow(Bloc)
#create blankd data.frame
G <- data.frame(matrix(ncol=3), stringsAsFactors=FALSE)
G[,1:3] <- as.character(G[,1:3])
#G <- data.frame(sdw=character(), sd=character(), ID= character())
colnames(G) <- c("sdw", "sd", "ID")
N <- M
mch <- as.data.frame(Bloc)
#Loop to sequentially fill data.frame
for (i in 1:M) {
# test if ID already in previous groups
if(Bloc[i,"ID"] %in% G$ID == FALSE) {
# convert element to vector to check for intersect
tm <- strsplit(x=Bloc[i, "sd"], split=", ")
mch$t <- numeric(length=M)
}
for (j in 1:N){
#if intersect exists apply code as 1 mch$t column
ff <- strsplit(x=mch[j, "sd"], split=", ")[[1]]
dd <- intersect (tm[[1]], ff)
if (identical(dd, character(0))== FALSE) mch[j,"t"] = 1
}
submch <- subset(mch, t == 1 )
ID <- submch$ID
Group1 <- sort((unlist(strsplit(paste0(submch$sdw, collapse=","), ","))))
Group1 <- unique(gsub(" ","", Group1))
sdw <- rep(paste0(Group1, collapse=", "), nrow(submch))
Group2 <- sort((unlist(strsplit(paste0(submch$sd, collapse=","), ","))))
Group2 <- unique(gsub(" ","", Group2))
sd <- rep(paste0(Group2, collapse=", "), nrow(submch))
G1 <- cbind(sdw, sd, ID)
G1 <- unique(G1)
G <- rbind(G, G1)
mch$t <- NULL
}
G <- unique(G)
G2 <- data.table(G, key="ID")
G2 <- G2[, list(sdw = paste0(sort(unique(unlist(strsplit(sdw, split=", ")))), collapse=", "),
sd = paste0(sort(unique(unlist(strsplit(sd, split=", ")))), collapse=", ")) , by = "ID"]
G2 <- data.table( G2, key=c("sd", "sdw"))
G2 <- unique(G2)以data.table形式获取输出
Bloc <- G2[-1,]
Bloc$ID <- NULL重复上面的循环,直到不再有交叉点。
repeat
{
N1 <- nrow(Bloc)
Bloc <- Bloc[ , list( ID = unlist( strsplit( sd , "," ) ) ) , by = list(sdw, sd) ]
Bloc$ID <- gsub("^\\s+|\\s+$", "", Bloc$ID)
Bloc <- data.table( Bloc , key = "ID" )
Bloc <- as.data.frame(Bloc)
M <- nrow(Bloc)
#create blankd data.frame
G <- data.frame(matrix(ncol=3), stringsAsFactors=FALSE)
G[,1:3] <- as.character(G[,1:3])
#G <- data.frame(sdw=character(), sd=character(), ID= character())
colnames(G) <- c("sdw", "sd", "ID")
N <- M
mch <- as.data.frame(Bloc)
#Loop to sequentially fill data.frame
for (i in 1:M) {
# test if ID already in previous groups
if(Bloc[i,"ID"] %in% G$ID == FALSE) {
# convert element to vector to check for intersect
tm <- strsplit(x=Bloc[i, "sd"], split=", ")
mch$t <- numeric(length=M)
}
for (j in 1:N){
#check if intersect exists and code accordingly
ff <- strsplit(x=mch[j, "sd"], split=", ")[[1]]
dd <- intersect (tm[[1]], ff)
if (identical(dd, character(0))== FALSE) mch[j,"t"] = 1
}
submch <- subset(mch, t == 1 )
ID <- submch$ID
Group1 <- sort((unlist(strsplit(paste0(submch$sdw, collapse=","), ","))))
Group1 <- unique(gsub(" ","", Group1))
sdw <- rep(paste0(Group1, collapse=", "), nrow(submch))
Group2 <- sort((unlist(strsplit(paste0(submch$sd, collapse=","), ","))))
Group2 <- unique(gsub(" ","", Group2))
sd <- rep(paste0(Group2, collapse=", "), nrow(submch))
G1 <- cbind(sdw, sd, ID)
G1 <- unique(G1)
G <- rbind(G, G1)
mch$t <- NULL
}
G <- unique(G)
G2 <- data.table(G, key="ID")
G2 <- G2[, list(sdw = paste0(sort(unique(unlist(strsplit(sdw, split=", ")))), collapse=", "),
sd = paste0(sort(unique(unlist(strsplit(sd, split=", ")))), collapse=", ")) , by = "ID"]
G2 <- data.table( G2, key=c("sd", "sdw"))
G2 <- unique(G2)
Bloc <- G2[-1,]
Bloc$ID <- NULL
N2 <- nrow(Bloc)
if (N1 == N2)
break
}输出
区块$sdw
[1] "SD1:FIELD, SD1:LUSH, SD23:SWITCH, SD32:TRUMPET, SD384:FR563, SD44:CANCEL, SD567:TREK"
[2] "SD12:PAINTING, SD183:WIRE, SD315:MONEY31, SD340:DUST, SD345:FOX, SD345:HOLE, SD387:ROLL, SD387:SPRING, SD42:CRAYON"
[3] "SD39:MATURE, SD455:TOMATO" Stack Overflow用户
发布于 2014-04-30 13:09:48
您可以尝试一些类似以下内容的内容:
id <- lapply(d, function(x) sapply(strsplit(x, ":"), "[", 1))
tbl <- table(unlist(id))若要分离ID,并在多个条目中查找哪些ID,请使用以下方法:
repeatIDs <- names(tbl)[tbl>1]
out <- list()现在,构建一个包含重复ID的压缩列表:
for (i in repeatIDs) {
ind <- sapply(id, function(x) any(i==x))
out[[i]] <- paste(unlist(d[ind]), collapse=", ")
}Stack Overflow用户
发布于 2014-05-01 11:40:27
我认为,如果在Gavin的答案中计算id,然后计算出所有的intersect(id[[j]],id[[k]]),或者甚至更好:
for (j in unique(unlist(id))) sapply(id,function(k) j%in%k)将为您提供交叉点(您将不得不按摩由该代码产生的TRUE TRUE FALSE...向量)。
编辑:下面是后续的内容:
id <- lapply(sdin, function(x) sapply(strsplit(x, ":"), "[", 1))
# id is
# [[1]]
# [1] "SD1" "SD44" "SD384" "SD32"
# [[2]]
# [1] "SD23" "SD1" "SD567"
# [[3]]
# [1] "SD42" "SD345" "SD183"
# [[4]]
# [1] "SD345" "SD340" "SD387"
# [[5]]
# [1] "SD455" "SD39"
# [[6]]
# [1] "SD12" "SD315" "SD387"
# [[7]]
# [1] "SD32" "SD1"
idnames<-unique(unlist(id))
# [1] "SD1" "SD44" "SD384" "SD32" "SD23" "SD567" "SD42"
# [8] "SD345" "SD183" "SD340" "SD387" "SD455" "SD39" "SD12"
# [15] "SD315"
matid<-matrix(NA,nrow=15,ncol=7)
for(k in 1:length(idnames) ) matid[k,] <- unlist(sapply(id, function(j) idnames[k]%in%j))
# [,1] [,2] [,3] [,4] [,5] [,6] [,7]
# [1,] TRUE TRUE FALSE FALSE FALSE FALSE TRUE
# [2,] TRUE FALSE FALSE FALSE FALSE FALSE FALSE
# [3,] TRUE FALSE FALSE FALSE FALSE FALSE FALSE
# [4,] TRUE FALSE FALSE FALSE FALSE FALSE TRUE
# [5,] FALSE TRUE FALSE FALSE FALSE FALSE FALSE
# [6,] FALSE TRUE FALSE FALSE FALSE FALSE FALSE
# [7,] FALSE FALSE TRUE FALSE FALSE FALSE FALSE
# [8,] FALSE FALSE TRUE TRUE FALSE FALSE FALSE
# [9,] FALSE FALSE TRUE FALSE FALSE FALSE FALSE
# [10,] FALSE FALSE FALSE TRUE FALSE FALSE FALSE
# [11,] FALSE FALSE FALSE TRUE FALSE TRUE FALSE
# [12,] FALSE FALSE FALSE FALSE TRUE FALSE FALSE
# [13,] FALSE FALSE FALSE FALSE TRUE FALSE FALSE
# [14,] FALSE FALSE FALSE FALSE FALSE TRUE FALSE
# [15,] FALSE FALSE FALSE FALSE FALSE TRUE FALSE该矩阵的每一行对应于"SDx“值之一,每列对应于输入d列表中的一个列表元素。您应该能够从那个表生成您的Venn图。
https://stackoverflow.com/questions/23387917
复制相似问题
腾讯云开发者
