
如何抓取外部web搜索
如何抓取外部web搜索
提问于 2014-05-30 15:42:38
我有一个名为http://www.op.nysed.gov/opsearches.htm的网站,例如,用户选择一个职业并输入许可方名称,然后单击Search按钮,将其带到一个新页面以显示结果。
例如,以下内容:
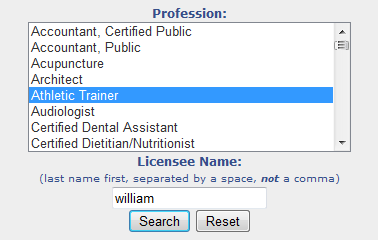
它显示以下结果:
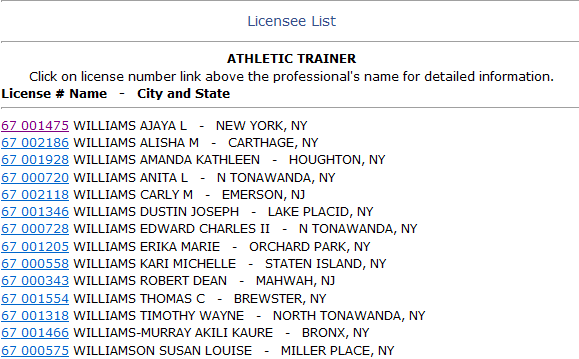
单击每个名称旁边的任意一组数字将显示信息,例如:
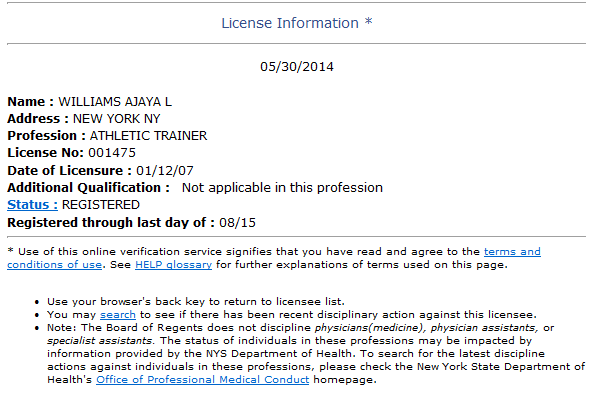
为了这个目的,我查看了抓取器、arachnode和其他网络爬虫,但我不太相信这是适合它的技术。
我被告知我们必须从页面上搜索那些搜索结果。有什么可以做的吗?
爬虫能像用户一样爬行搜索吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-05-30 16:34:34
Web爬行程序将为您提供目标web结构的本地副本,不太确定这是否是您想要的。
如果您想提取数据并以稍后查询的方式存储数据,那么您必须创建自己的应用程序。
首先,我们的想法是:
在web中手动导航,分析页面之间的帖子操作(例如,选择"Architect“并按下按钮时发送给服务器的内容,或者在许可证上指向链接的位置),找到真正的查询,发送哪些变量以及它们的格式,然后分析页面的HTML结构,找到可以与正则表达式引擎一起使用的模式。
这将是一个困难的部分,您必须分析传出和传入的HTTP查询(火狐中的LiveHTTP头可以帮助您很大程度上帮助您)在您的程序中模拟它们,并构造可实现的正则表达式模式(测试正则表达式RegEx教练非常方便)。
一旦您知道了如何在页面结构中导航并拥有了剥离数据的模式,其余的就相对容易了,使用WebClient创建客户机、浏览结构、剥离必要的数据并将其存储在DB中。
正如你所看到的,这是一个非常宽泛的答案,但因为你的问题也很宽泛。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/23958408
复制相关文章
相似问题
腾讯云开发者
