
Linux和unicode
Linux和unicode
提问于 2014-07-29 04:48:52
我对char编码unicode的了解(或者我认为我知道)与本文中的内容一样多:http://www.joelonsoftware.com/articles/Unicode.html。
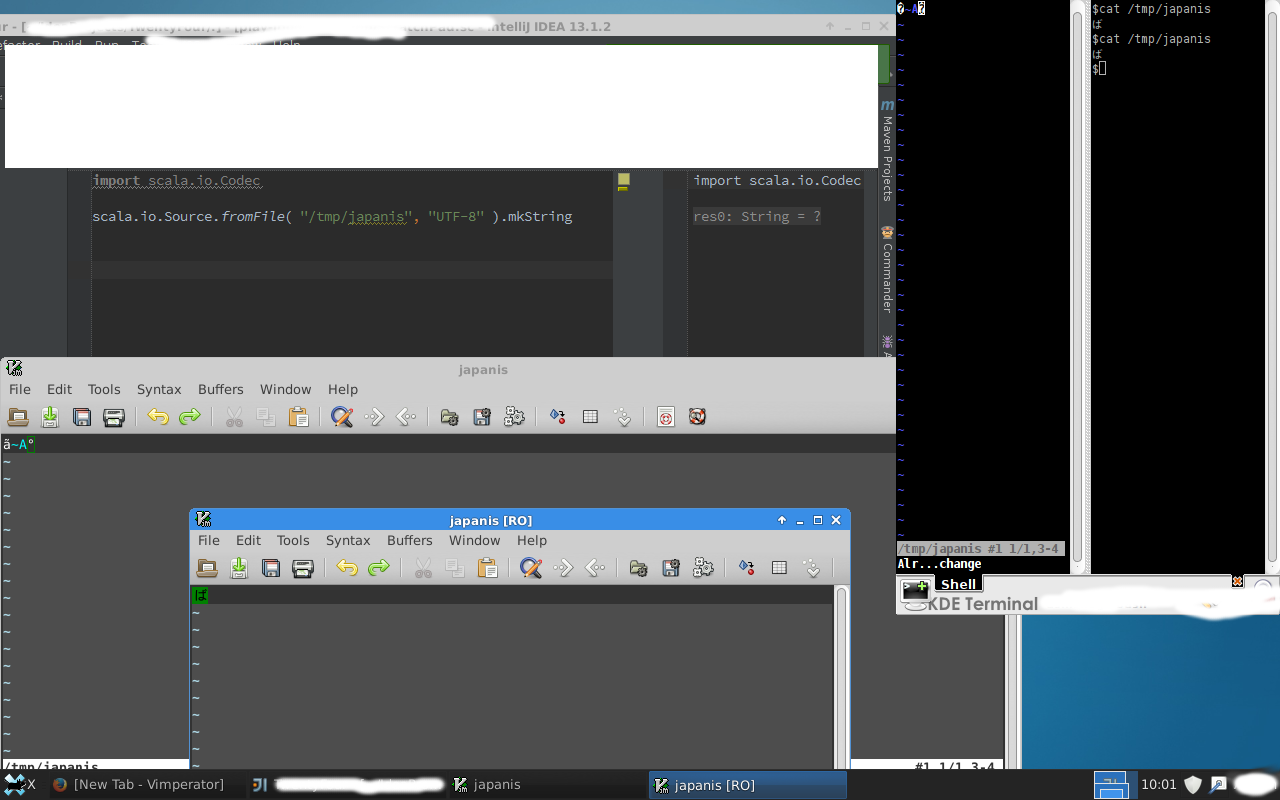
我在一个文件中保存了一个日文字符,并以多种方式打开它给了我多个结果。
逆时针方向(大致)
- 里面的“猫”给我看了正确的结果。
- 雅库克里面的维姆并不能证明这一点!
- 从yakuake打开的gvim也表明它是错误的。(屏幕中央较大的gvim )
- 从Alt-F2打开的gvim显示正确,底部gvim。
- Intellij打开它直接表明它是正确的。(不在图像中)
- 在Intellij中使用scala读取显示它是错误的。
scala.io.Source.fromFile( , "UTF-8" ).mkString
有人能告诉我这上面是什么吗?特别是维姆矛盾?我可以忍受Linux(X)和Intellij的任意行为,但是vim这样做告诉我,我的理解是错误的。
编辑:要回答@ answer 3666209的问题,所有vim/gvim都有“空”文件编码。
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-07-29 14:53:35
谢谢大家的回答!
vim不一致的原因,vims的“编码”错误,分别从终端和单独打开。解决方法是:在vim中设置encoding=utf8。
另外,将我的终端编码设置为utf8,否则cat会给出错误的结果。
对于java,请使用export JAVA_TOOL_OPTIONS='-Dfile.encoding=UTF-8'
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25008412
复制相关文章
相似问题
腾讯云开发者
