
R中已知分布下数据点拟合概率的计算
R中已知分布下数据点拟合概率的计算
提问于 2014-09-19 21:47:50
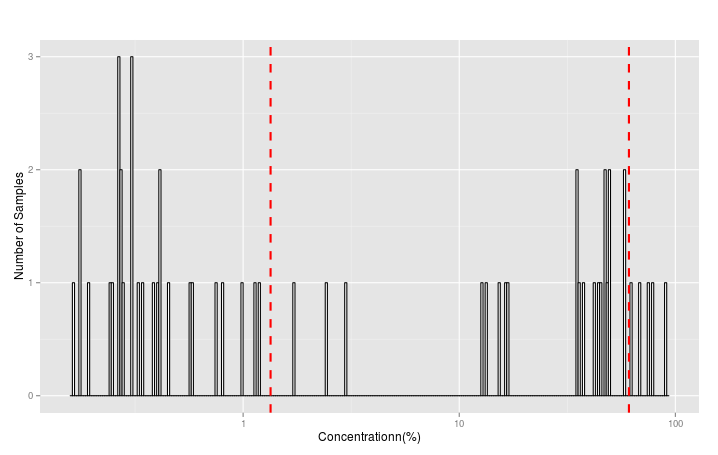
我有一组样本,每个样本都含有元素A的浓度,在下面的柱状图X轴上用对数标度显示。相同浓度的样品数显示在Y轴上.正如您在直方图中看到的那样,分布类似于多模分布。基于我正在使用的实验,左模态,我知道一个事实,那就是仪器噪声(,这是我如何定义噪声:那些数据点大于data+3*standard偏差的平均值),但右模态是真实的数据。所以,基本上,对于那些在左模态上显示浓度的样本,实际浓度值为零。
我的问题是;
1-我需要一个测量值(p值),它给我一个概率值,从右边模态中的每个数据点属于(或不)属于左模态(适合或不适合)。
2-如果我在右边只有一个数据点,而不是在右边的另一个分布(正确的模式),我将如何度量这个数据点是否符合或不符合正确的模式的概率(又名。(噪音)
先谢谢你。
PS:
我能在R中实现的任何提示都会更好。
2-红线是两个模态的平均值。
回答 1
Stack Overflow用户
发布于 2014-09-25 12:38:03
更新:
我使用单个样本t检验来比较右侧的每个数据点和左侧的分布。然后我计算了t检验的p值。单个样本的t检验可以用R中的regualr t检验函数来完成,除了不需要定义第二分布外,还需要定义"mu“的值,即我们要与分布比较的数据点的值。这基本上就像我们想要将左边分布的平均值与极限进行比较的p值(例如,左边分布的平均值比x mu=x小的可能性多大)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/25942846
复制相关文章
相似问题
腾讯云开发者
