
DocumentDB中每个集合的单个或多个实体
在DB文档中,每个集合应该有一个实体吗?
考虑到我在下图中有外键关系:
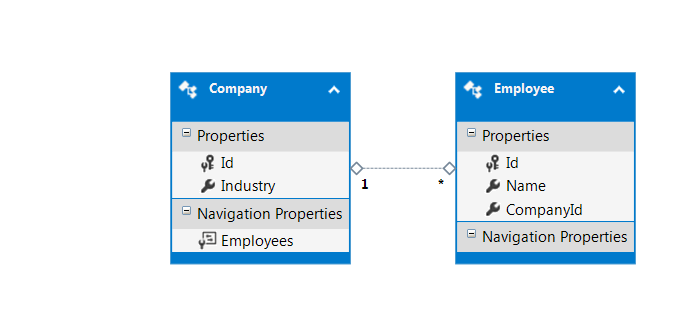
我应该创建两个集合,一个用于员工,另一个用于公司。或者我应该把它们储存在一个单一的收藏中?
我读过here,在documentdb中,存储过程的作用域、触发器等都在集合中。因此,通过将不同的实体分割到单独的集合中,我就失去了开箱即用的功能。
因此,最好将这两个类转储为单个实体,如下所示:
{
"Id": 1001,
"Industry": "Software",
"Employees": [
{
"Id": 10011,
"Name": "John Doe",
"CompanyId": 1001
},
{
"Id": 10012,
"Name": "Jane Doe",
"CompanyId": 1001
}
]
}在DocumentDB中实现相关实体的标准实践是什么?
回答 3
Stack Overflow用户
发布于 2014-12-14 03:25:45
通常情况下,每个集合存储多个实体类型是好的。是否将实体类型存储到单个文档中需要更多的思考。
正如David提到的,如何对数据进行建模有点主观。
在集合中存储多个实体类型
首先..。让我们讨论如何在集合中存储多个实体。DocumentDB集合是而不是表。集合不强制架构;换句话说,可以在同一集合中使用不同的架构存储不同类型的文档。您可以通过向文档中添加类型属性来跟踪不同类型的实体。
您应该将集合视为执行查询和事务的分区和边界的一个单元。因此,在同一集合中存储不同实体类型的一个巨大好处是,您可以通过sprocs立即获得事务支持。
在文档中存储多个实体类型
是否在单个文档中存储多个实体类型需要更多的思考。这通常是指非规范化(通过在单个文档中嵌入数据来捕获数据之间的关系)和规范化(通过创建到o其他文档的弱链接来捕获数据之间的关系)。
通常,de-normalizing提供更好的读取性能。
应用程序可能需要较少的查询和更新来完成公共操作。
通常,在下列情况下使用非规范化数据模型:
- 有实体间的“包含”关系
- 在实体之间有一对一的关系
- 非规范化数据变化不频繁。
- 没有绑定,非规范化数据将不会增长。
- 非规范化数据与文档中的数据是不可缺少的。
非规范化数据模型的示例:
{
"Id": 1001,
"Type": "Company",
"Industry": "Software",
"Employees": [
{
"Id": 10011,
"Type": "Employee",
"Name": "John Doe"
},
{
"Id": 10012,
"Type": "Employee",
"Name": "Jane Doe"
}
]
}通常,规范化提供更好的写入性能。
提供比非规范化更灵活的功能。
客户端应用程序必须发出后续查询才能解析引用。换句话说,规范化的数据模型可能需要更多的往返到服务器。
通常,使用规范化数据模型:
- 当去正常化会导致数据重复,但不会提供足够的读取性能优势,超过复制的含意。
- 表示一对多的关系
- 代表多到多的关系。
- 相关数据频繁变化
规范化数据模型的示例:
{
"Id": 1001,
"Type": "Company",
"Industry": "Software"
}
{
"Id": 10011,
"Type": "Employee",
"Name": "John Doe",
"CompanyId": 1001
}
{
"Id": 10012,
"Type": "Employee",
"Name": "Jane Doe",
"CompanyId": 1001
}混合逼近
在正规化和非正常化之间做出选择并不一定是一个黑白的选择。我经常发现,成功的设计模式是一种混合方法,在这种方法中,您可以选择对对象的部分字段集合进行规范化,并对其他字段进行去规范化。
换句话说,您可以选择去规范化频繁读取的稳定(或不变的)属性,以减少后续查询的需要,而对频繁写入/变异的字段进行规范化,以减少扇出写入的需要。
混合办法的例子:
// Author documents:
[{
"id": 1,
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": [1, 2, 3],
"images": [{
"thumbnail": "http://....png"
}, {
"profile": "http://....png"
}, {
"large": "http://....png"
}]
}, {
"id": 2,
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": [1, 4, 5],
"images": [{
"thumbnail": "http://....png"
}]
}]
// Book documents:
[{
"id": 1,
"name": "DocumentDB 101",
"authors": [{
"id": 1,
"name": "Thomas Andersen",
"thumbnailUrl": "http://....png"
}, {
"id": 2,
"name": "William Wakefield",
"thumbnailUrl": "http://....png"
}]
}, {
"id": 2,
"name": "DocumentDB for RDBMS Users",
"authors": [{
"id": 1,
"name": "Thomas Andersen",
"thumbnailUrl": "http://....png"
}, ]
}]Stack Overflow用户
发布于 2014-12-13 15:04:59
你的问题有点主观,因为你要求的是实体设计,对此,没有一个正确的答案。
但是:从更客观的角度来看:没有什么可以阻止您在集合中拥有多个实体类型(例如,Company文档类型和Employee文档类型,在您的例子中)。
您需要自己包含某种类型的提示(可能是type属性),以帮助在运行查询时区分这两种提示。但是,通过将这两种类型都包含在同一个集合中,现在可以在其中使用集合范围。关于type属性:由于DocumentDB默认对所有属性进行索引,所以type属性很容易集成到查询中。
编辑删除了大约3集每容量单位的部分,因为当DocumentDB从预览转移到生产时,这种安排就被删除了。
Stack Overflow用户
发布于 2020-10-16 07:10:42
在过去5年中,Cosmos DB中发生了许多变化,影响数据结构设计的最重要的变化之一是可以创建许多容器并在所有容器之间共享RU。
在同一个容器中组合多个实体类型仍然很好(集合的新名称)。然而,在2020年,将每个实体类型放在一个单独的容器中也是可以的。
当然,这取决于您的应用程序的需要,一个非常重要的考虑是您打算如何阅读这些信息。但是,这里有一个通用的数据结构和方法,您可以考虑:
- 将每个实体保存在各自的容器中。
- 包含一个具有实体名称的属性
- 以一种方式选择分区键,这样您就不会在一个分区中有超过10 GB的数据。
- 确定由于大量调用而需要最佳性能的读取。
- :将数据复制到为预期读取优化的容器
对于要优化的读取,请将数据复制到专门用于该目的的新容器中,并确保分区键与查询的主参数匹配。您可以将许多不同的实体放在同一个容器中。
这样,您会发现读取操作的效率要高很多倍。
Cosmos DB性能在很大程度上取决于数据量,如果您确保您的文档易于通过分区键访问,那么在单个文档中放置大量数据而不是将它们保存在单独的文档中,不会获得任何显著的性能提升。
示例
你有两个容器:
- 订单
- 订单-详情
订单由productId划分,订单详细信息由orderId划分。但是,对于显示单个用户订单历史的新功能,不仅要通过userId属性获取订单,而且还要对每个订单进行后续调用,以获取放置在单独分区中的订单详细信息,这需要花费太多的RU。
幸运的是,这两个文档都包含一个userId属性。您要做的是创建一个新容器(可能称为orders-by-user ),并将userId属性配置为分区键。然后将所有文档从order-details、orders、和复制到这个容器中。
现在,您可以通过userId对这个容器进行高效的读取。
您可以使用Data、基于变更提要的Azure函数进行复制,很快就会有一个内置特性(参见注释):https://stackoverflow.com/a/64355508/392362
https://stackoverflow.com/questions/27456564
复制相似问题
腾讯云开发者
