
用LINQ计算百分位数
全,
在回顾了StackOverflow和更广泛的互联网之后,我仍然在努力用LINQ高效地计算百分位数。
其中,百分位数是统计中使用的一种度量,指示某一组观测中给定百分比的值低于该值。下面的示例尝试将一个值列表转换为一个数组,其中每个(唯一)值都用关联百分位数表示。列表的min()和max()必须是返回数组百分位数的0%和100%。
使用LINQPad,下面的代码生成所需的输出VP[]:
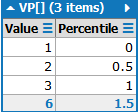
这可以解释为:-在0%时,最小值是1-在100%时,最大值是3-在50%时,最小值和最大值之间是2。
void Main()
{
var list = new List<double> {1,2,3};
double denominator = list.Count - 1;
var answer = list.Select(x => new VP
{
Value = x,
Percentile = list.Count(y => x > y) / denominator
})
//.GroupBy(grp => grp.Value) --> commented out until attempted duplicate solution
.ToArray();
answer.Dump();
}
public struct VP
{
public double Value;
public double Percentile;
}但是,当"list“包含重复条目(例如,1,2,*2,**3)时,这将返回一个不正确的VP[]:
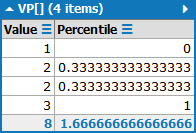
我试图按列表中的唯一值进行分组(包括".GroupBy(grp => grp.Value)"),但没有得到预期的结果(Value =2,&百分位数= 0.666):
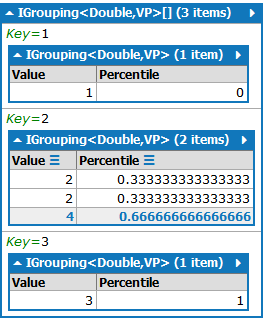
欢迎所有建议。考虑到"list.Count(y => x> y)“的重复迭代,这是否是一种有效的方法。
一如既往,谢谢香农
回答 2
Stack Overflow用户
发布于 2016-05-18 02:44:41
我不太明白这个问题的要求。当我运行被接受的答案的代码时,我得到了以下结果:
但是,如果我将输入更改为:
var dataSet = new List<double> { 1, 1, 1, 1, 2, 3, 3, 3, 2 };然后...I得到以下结果:
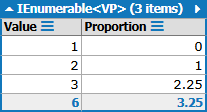
使用行“列表的min()和max()必须是返回数组百分位数的0%和100%”。在我看来,OP要求的值从0到1,但是更新的结果超过了1。
在我看来,第一个值应该是0%也是错误的,因为我不知道这在数据上下文中意味着什么。
在阅读了链接的维基百科页面后,OP似乎实际上试图对计算百分位数进行反向计算。事实上,这篇文章说0的百分位数是没有定义的。这是有意义的,因为0的百分位数将是值的空集--空集的最大值是多少?
OP似乎在从值中计算百分位数。因此,在这个意义上,并且知道0是未定义的,似乎最适合计算的值是等于或低于集合中每个不同值的值的百分比。
现在,如果我使用Microsoft的反应性框架团队的交互式扩展(NuGet "Ix-Main"),那么我可以运行以下代码:
var dataSet = new List<double> { 1, 1, 1, 1, 2, 3, 3, 3, 2 };
var result =
dataSet
.GroupBy(x => x)
.Scan(
new VP()
{
Value = double.MinValue, Proportion = 0.0
},
(a, x) =>
new VP()
{
Value = x.Key,
Proportion = a.Proportion + (double)x.Count() / dataSet.Count
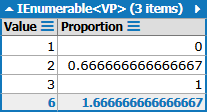
});我得到了这个结果:
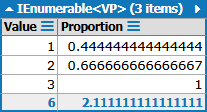
这告诉我,大约44%的值为1;约67%的值为1或2;100%的值为1、2或3。
在我看来,这是最符合逻辑的需求计算。
Stack Overflow用户
发布于 2014-12-29 03:47:10
void Main()
{
var list = new List<double> {1,2,3};
double denominator = list.Count - 1;
var answer = list.OrderBy(x => x).Select(x => new VP
{
Value = x,
Proportion = list.IndexOf(x) / denominator
})
.ToArray();
answer.Dump();
}
public struct VP
{
public double Value;
public double Proportion;
}https://stackoverflow.com/questions/27682779
复制相似问题
腾讯云开发者
