
使用带权重的scipy.optimize.curve_fit
根据文档,参数sigma可以用来设置数据点的权值。这些“描述”1西格玛错误时,参数absolute_sigma=True。
我有一些人工正态分布噪声的数据,这些数据各不相同:
n = 200
x = np.linspace(1, 20, n)
x0, A, alpha = 12, 3, 3
def f(x, x0, A, alpha):
return A * np.exp(-((x-x0)/alpha)**2)
noise_sigma = x/20
noise = np.random.randn(n) * noise_sigma
yexact = f(x, x0, A, alpha)
y = yexact + noise如果我想将嘈杂的y安装到f中,使用curve_fit设置为什么?这里的文档不是很具体,但我通常使用1/noise_sigma**2作为权重:
p0 = 10, 4, 2
popt, pcov = curve_fit(f, x, y, p0)
popt2, pcov2 = curve_fit(f, x, y, p0, sigma=1/noise_sigma**2, absolute_sigma=True)不过,这似乎并没有改善身体的健康状况。
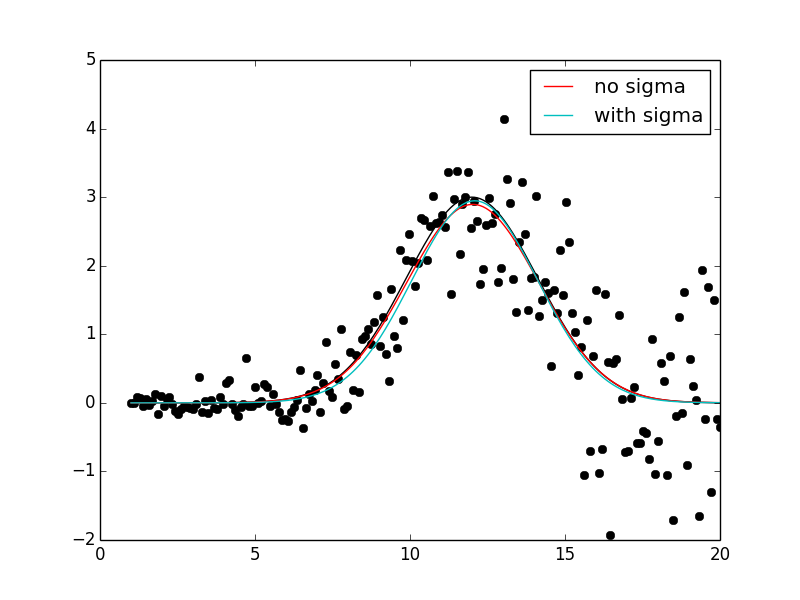
该选项是否仅用于通过协方差矩阵更好地解释拟合不确定性?这两个跟我说的有什么区别?
In [249]: pcov
Out[249]:
array([[ 1.10205238e-02, -3.91494024e-08, 8.81822412e-08],
[ -3.91494024e-08, 1.52660426e-02, -1.05907265e-02],
[ 8.81822412e-08, -1.05907265e-02, 2.20414887e-02]])
In [250]: pcov2
Out[250]:
array([[ 0.26584674, -0.01836064, -0.17867193],
[-0.01836064, 0.27833 , -0.1459469 ],
[-0.17867193, -0.1459469 , 0.38659059]])回答 1
Stack Overflow用户
发布于 2018-12-15 01:44:45
至少在版本1.1.0中,参数sigma应该等于每个参数的错误。具体来说,文档说:
1-d西格玛应包含数据中误差的标准差值.在这种情况下,优化的函数是chisq = sum((r / sigma) ** 2)。
就你而言,这将是:
curve_fit(f, x, y, p0, sigma=noise_sigma, absolute_sigma=True)我查看了来源代码,并验证了当您以这种方式指定sigma时,它会最小化((f-data)/sigma)**2。
顺便说一句,当你知道错误的时候,这通常是你想要最小化的。给定模型data的观察点f的可能性是由以下方法给出的:
L(data|x0,A,alpha) = product over i Gaus(data_i, mean=f(x_i,x0,A,alpha), sigma=sigma_i)如果你把负日志变成(不依赖于参数的常数):
-log(L) = sum over i (f(x_i,x0,A,alpha)-data_i)**2/(sigma_i**2)这只是个骗局。
我编写了一个测试程序来验证curve_fit确实返回了正确指定的西格玛值:
from __future__ import print_function
import numpy as np
from scipy.optimize import curve_fit, fmin
np.random.seed(0)
def make_chi2(x, data, sigma):
def chi2(args):
x0, A, alpha = args
return np.sum(((f(x,x0,A,alpha)-data)/sigma)**2)
return chi2
n = 200
x = np.linspace(1, 20, n)
x0, A, alpha = 12, 3, 3
def f(x, x0, A, alpha):
return A * np.exp(-((x-x0)/alpha)**2)
noise_sigma = x/20
noise = np.random.randn(n) * noise_sigma
yexact = f(x, x0, A, alpha)
y = yexact + noise
p0 = 10, 4, 2
# curve_fit without parameters (sigma is implicitly equal to one)
popt, pcov = curve_fit(f, x, y, p0)
# curve_fit with wrong sigma specified
popt2, pcov2 = curve_fit(f, x, y, p0, sigma=1/noise_sigma**2, absolute_sigma=True)
# curve_fit with correct sigma
popt3, pcov3 = curve_fit(f, x, y, p0, sigma=noise_sigma, absolute_sigma=True)
chi2 = make_chi2(x,y,noise_sigma)
# double checking that we get the correct answer
xopt = fmin(chi2,p0,xtol=1e-10,ftol=1e-10)
print("popt = %s, chi2 = %.2f" % (popt,chi2(popt)))
print("popt2 = %s, chi2 = %.2f" % (popt2, chi2(popt2)))
print("popt3 = %s, chi2 = %.2f" % (popt3, chi2(popt3)))
print("xopt = %s, chi2 = %.2f" % (xopt, chi2(xopt)))其中产出:
popt = [ 11.93617403 3.30528488 2.86314641], chi2 = 200.66
popt2 = [ 11.94169083 3.30372955 2.86207253], chi2 = 200.64
popt3 = [ 11.93128545 3.333727 2.81403324], chi2 = 200.44
xopt = [ 11.93128603 3.33373094 2.81402741], chi2 = 200.44如您所见,当您将chi2指定为curve_fit的参数时,curve_fit确实被正确地最小化了。
至于为什么改进不是“更好”,我不太确定。我唯一的猜测是,如果不指定一个sigma值,您就会隐式地假设它们是相等的,并且在适合的部分数据上(峰值),错误“大致”相等。
为了回答你的第二个问题,不,西格玛选项不仅用于改变协方差矩阵的输出,它实际上改变了被最小化的内容。
https://stackoverflow.com/questions/27696324
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号