
Java 8的字符串重复特性
由于Java中的String (和其他语言一样)占用了大量内存,因为每个字符都消耗两个字节,所以Java 8引入了一个名为String De2018的新特性,它利用了char数组是字符串内部的和最终的,这样JVM就可以处理它们了。
到目前为止,我已经读过这个例子了,但是由于我不是一个专业的java程序员,所以我很难理解这个概念。
上面写的是,
已经考虑过各种字符串复制策略,但现在实现的策略遵循以下方法:每当垃圾收集器访问String对象时,它都会注意char数组。它获取它们的散列值,并将其与对数组的弱引用一起存储。一旦找到另一个具有相同哈希码的字符串,它就会逐个字符对它们进行比较。如果它们也匹配,一个字符串将被修改并指向第二个字符串的char数组。然后,第一个char数组不再被引用,可以被垃圾收集。 当然,整个过程会带来一些开销,但受到严格的限制。例如,如果在一段时间内找不到重复的字符串,则将不再检查该字符串。
我的第一个问题,
由于最近在Java8UPDATE 20中添加了这个主题,因此仍然缺乏相关的资源,这里有谁能分享一些关于它如何帮助减少String在Java中使用的内存的实际例子吗?
编辑:
上面的链接显示,
一旦找到另一个具有相同哈希码的字符串,就会将它们逐字符进行比较。
我的第二个问题,
如果两个String的哈希码是相同的,那么当发现两个String具有相同的哈希码时,为什么要通过char将它们进行比较呢?
回答 4
Stack Overflow用户
发布于 2015-01-14 18:06:46
假设您有一本电话簿,其中包含一个String firstName和一个String lastName。碰巧,在你的电话簿上,有10万人拥有相同的firstName = "John"。
因为您从数据库或文件中获取数据,所以这些字符串不会被嵌入,所以您的JVM内存包含char数组{'J', 'o', 'h', 'n'} 100,000次,每一个字符串一次。这些数组中的每一个都需要20字节的内存,所以这些100 arrays占用了2MB的内存。
使用去重复,JVM将意识到" John“多次被复制,并使所有这些John字符串指向相同的底层char数组,从而将内存使用量从2MB减少到20字节。
您可以在杰普中找到更详细的解释。特别是:
目前,许多大型Java应用程序在内存方面遇到了瓶颈。测量表明,这些类型的应用程序中大约25%的Java堆活动数据集是由String对象使用的。此外,这些字符串对象中大约有一半是重复的,重复表示
string1.equals(string2)为真。堆上有重复的字符串对象实质上是浪费内存。 ..。 实际的预期收益最终达到了大约10%的堆减少。请注意,这个数字是基于广泛的应用程序的计算平均值。特定应用程序的堆减少可能有很大的变化,无论是向上还是向下。
Stack Overflow用户
发布于 2015-01-14 22:40:08
@assylias的回答基本告诉你它是如何工作的,并且是非常好的答案。我已经测试了一个使用字符串删除的生产应用程序,并取得了一些结果。这个网络应用程序大量使用Strings,所以我认为它的优势非常明显。
要启用字符串删除,必须添加这些JVM参数(至少需要Java 8u20):
-XX:+UseG1GC -XX:+UseStringDeduplication -XX:+PrintStringDeduplicationStatistics最后一个是可选的,但就像名字说的那样,它会显示字符串的去重复统计信息。这是我的:
[GC concurrent-string-deduplication, 2893.3K->2672.0B(2890.7K), avg 97.3%, 0.0175148 secs]
[Last Exec: 0.0175148 secs, Idle: 3.2029081 secs, Blocked: 0/0.0000000 secs]
[Inspected: 96613]
[Skipped: 0( 0.0%)]
[Hashed: 96598(100.0%)]
[Known: 2( 0.0%)]
[New: 96611(100.0%) 2893.3K]
[Deduplicated: 96536( 99.9%) 2890.7K( 99.9%)]
[Young: 0( 0.0%) 0.0B( 0.0%)]
[Old: 96536(100.0%) 2890.7K(100.0%)]
[Total Exec: 452/7.6109490 secs, Idle: 452/776.3032184 secs, Blocked: 11/0.0258406 secs]
[Inspected: 27108398]
[Skipped: 0( 0.0%)]
[Hashed: 26828486( 99.0%)]
[Known: 19025( 0.1%)]
[New: 27089373( 99.9%) 823.9M]
[Deduplicated: 26853964( 99.1%) 801.6M( 97.3%)]
[Young: 4732( 0.0%) 171.3K( 0.0%)]
[Old: 26849232(100.0%) 801.4M(100.0%)]
[Table]
[Memory Usage: 2834.7K]
[Size: 65536, Min: 1024, Max: 16777216]
[Entries: 98687, Load: 150.6%, Cached: 415, Added: 252375, Removed: 153688]
[Resize Count: 6, Shrink Threshold: 43690(66.7%), Grow Threshold: 131072(200.0%)]
[Rehash Count: 0, Rehash Threshold: 120, Hash Seed: 0x0]
[Age Threshold: 3]
[Queue]
[Dropped: 0]这是运行应用程序10分钟后的结果。如您所见,字符串重复执行了452次和801.6 MB字符串。字符串重复检查27000 000字符串。当我将Java 7中的内存消耗与标准的并行GC和Java8u20与G1 GC和启用的字符串重复进行比较时,堆丢弃了大约50%的:
Java 7并行GC
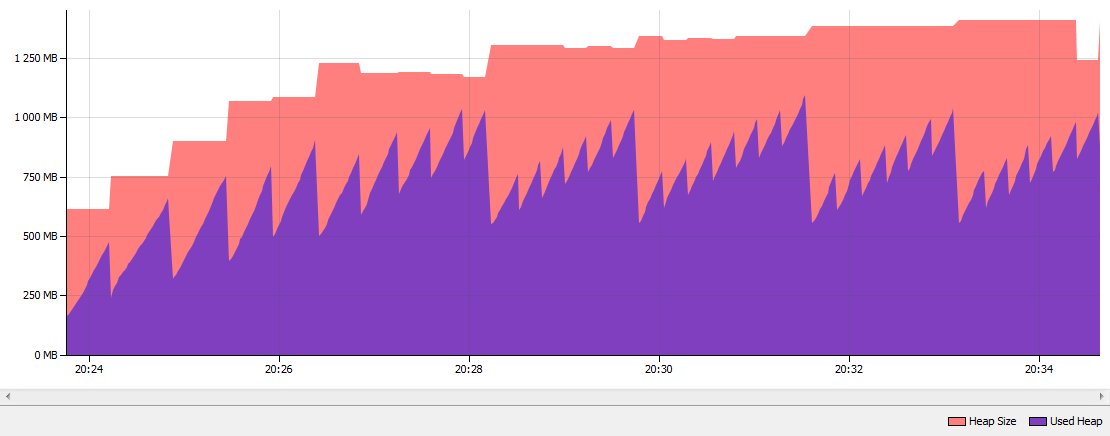
Java 8 G1 GC与字符串重复

Stack Overflow用户
发布于 2015-01-14 19:12:56
既然你的第一个问题已经回答了,我就回答你的第二个问题。
String对象必须按字符进行比较,因为虽然相等的Objects意味着相同的散列,但逆不一定是正确的。
hashcode()方法的适用规范如下:
- 如果根据
equals(Object)方法两个对象相等,那么对两个对象调用hashCode方法必须产生相同的整数结果。 - 如果两个对象根据
equals(java.lang.Object)方法是不相等的,那么对两个对象调用hashCode方法就不需要产生不同的整数结果。..。
这意味着,为了保证平等,需要对每个字符进行比较,以便确认这两个对象的相等性。它们首先比较hashCode,而不是使用equals,因为它们使用哈希表作为引用,这提高了性能。
https://stackoverflow.com/questions/27949213
复制相似问题
腾讯云开发者
