
从文本文件中提取节名和开始页
我有一个输入文本文件像这样(“.”)实际上不在原始文本中,而是被我用来忽略一些冗长且可能不相关的文本;^L“表示每一页的开头(注意:"^L”被键入为控制字符,而不是字符"^“和字符”L“):
(Begin text)
.. A language ...
^LIntroduction
6
A preferable alternative is ...
1.2.1 Abstraction by Parameters
Abstraction allows us, ...
^L1.2 Abstraction
7
and ...
1.2.2 Abstraction by Specification
... ...
^LAn Overview of CLU
14
In addition to ...
2.1.2 Type Checking
...
(End text)期望的输出是:
1.2.1 Abstraction by Parameters 6
1.2.2 Abstraction by Specification 7
2.1.2 Type Checking 14我想要做的是提取,第三级部分名称和,它们出现的页面编号是。
- 第三级节名总是出现在一行中。
- 第三级节名出现的页码是出现在单行中的第一个数字,就在节名之前的最后一个"^L“之后。
我想知道如何用Python编写一个程序来实现这一点?
到目前为止,我是这么想的:
- 匹配(第三级节名)的regex模式是
^\s*\d+\.\d+\.\d+.*\n - 在每一页中,"^L“表示页面的开头(注意:"^L”是作为控制字符输入的,而不是字符"^“和字符"L")。将从"^L“到页的页码匹配的正则模式是
^^L.*\n.*^\s*\d+\s*\n
我仍然不知道如何继续下去。谢谢你的启发!
回答 2
Stack Overflow用户
发布于 2015-02-14 19:45:16
你必须了解这篇文章--我需要仔细检查一下,才能完成这篇文章。页面编号看起来像- FormFeedPageNoLineFeed或LineFeedPageNoLineFeed,一个页面上可以有多个三级标题,所以从一个正则表达式开始,该表达式将提取整页并捕获页面号。
pages = re.compile(r'[\n\f](\d+)\n.*?(?=[\n\f](\d+)\n)', flags = re.DOTALL | re.MULTILINE)然后搜索每一页的第三级标题,并把它放在一起。
third_level = re.compile('\n(\d+\.\d+\.\d+[^\n]*)')
for page in pages.finditer(s):
page_no = page.group(1)
for item in third_level.finditer(page.group()):
print '{}\t{}'.format(item.group(1), page_no)这产生了54个三级标题。不幸的是,它对你的文本是独一无二的。在我花了很长时间才弄明白这一点的时候,我可以用一个好的文本编辑器半手动地提取信息,这个编辑器可以进行正则表达式搜索(这就是我为找出并验证它所做的)。
您可能可以改进pages --结合了前瞻性断言的.*?闻起来有点难闻。
编辑,提取第一级和第二级标题,然后与第三级标题相结合。是OP文件stuff.txt的唯一
import re
with open('stuff.txt') as f:
s = f.read()提取内容和附录信息,附录是分开提取的,以简化合并。
content_item = re.compile('\d+\.?\d*? [^\n]*')
appendix_item = re.compile('Appendix[^\n]*|[ABC]\.[^\n]*')
# Indices to limit the contents search
content_start = re.search('\f\fContents', s).span()[1]
content_end = re.search('\f\fPreface', s).span()[0]
content_items = content_item.findall(s, content_start, content_end)
appendices = appendix_item.findall(s, content_start, content_end)现在找到所有的三级标题和页码-与上面相同,但存储在一个列表中,
third_level = re.compile('\n(\d+\.\d+\.\d+[^\n]*)')
pages = re.compile(r'[\n\f](\d+)\n.*?(?=[\n\f](\d+)\n)', flags = re.DOTALL | re.MULTILINE)
third_levels = list()
for page in pages.finditer(s, content_end):
page_no = page.group(1)
for item in third_level.finditer(page.group()):
third_levels.append('{}\t{}'.format(item.group(1), page_no))合并内容和third_level标题,排序,并添加附录标题。
a = content_items + third_levels
def key(item):
'''Extract digits from the beginning of item for a sort key.
item is a string
>>> key('1 ABC')
(1, None, None)
>>> key('1.2 ABC')
(1, 2, None)
>>> key('1.2.3 ABC')
(1, 2, 3)
>>>
'''
item = item.split()
item = item[0].split('.')
a, b, c = None, None, None
try:
a = int(item[0])
except ValueError as e:
pass
try:
b = int(item[1])
except IndexError as e:
pass
try:
c = int(item[2])
except IndexError as e:
pass
return a, b, c
a.sort(key = key)
a.extend(appendices)Stack Overflow用户
发布于 2015-02-14 15:07:34
您需要分隔的字符是\x0C / ^L / chr(12),它是http://en.wikipedia.org/wiki/Page_break#Form_feed字符。
迭代法
import re
def foo(lines):
name = ''
pages = []
page_break_char = chr(0xC)
for line in lines:
if re.match('^\s*\d+\.\d+\.\d+.*', line):
name = line
elif re.match('^\d+$', line):
pages.append(line)
elif page_break_char in line:
if name:
yield name, pages
del pages[:]
if name:
yield name, pages使用
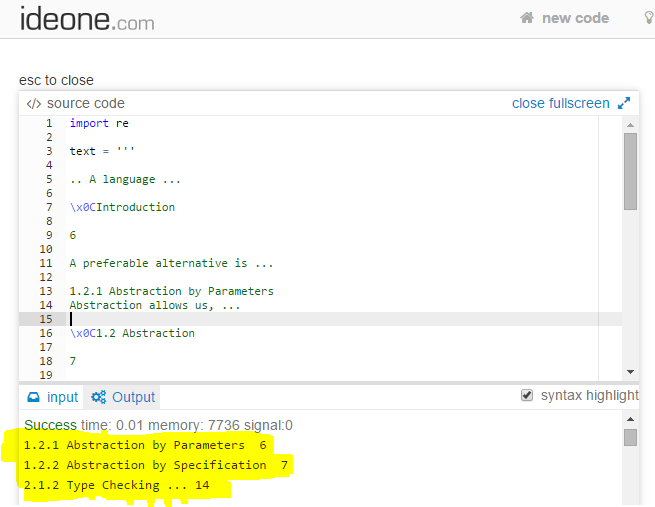
text = '''
.. A language ...
\x0CIntroduction
6
A preferable alternative is ...
1.2.1 Abstraction by Parameters
Abstraction allows us, ...
\x0C1.2 Abstraction
7
and ...
1.2.2 Abstraction by Specification
... ...
\x0CAn Overview of CLU
14
In addition to ...
2.1.2 Type Checking ...
'''
lines = text.split('\n')
for name, pages in foo(lines):
print name, ' '.join(pages)输出
在线演示
https://stackoverflow.com/questions/28516246
复制相似问题
腾讯云开发者
