
gaussian_kde与循环数据
我用gaussian_kde得到一些双峰数据的概率密度。但是,由于我的数据是角的(它的方向是度),所以当值出现在极限附近时,我会遇到一个问题。下面的代码给出了两个kde示例,当域为0-360时,由于它不能处理数据的循环性质,所以估计值为0~360。pdf需要在单元圆上定义,但是我在scipy.stats中找不到适合这种类型数据的任何东西(von分布在那里,但只对单峰数据工作)。以前有没有人碰到过这个?有什么(更好的基于python的)可以用来估计单位圆上的双峰pdf吗?
import numpy as np
import scipy as sp
from pylab import plot,figure,subplot,show,hist
from scipy import stats
baz = np.array([-92.29061004, -85.42607874, -85.42607874, -70.01689348,
-63.43494882, -63.43494882, -70.01689348, -70.01689348,
-59.93141718, -63.43494882, -59.93141718, -63.43494882,
-63.43494882, -63.43494882, -57.52880771, -53.61564818,
-57.52880771, -63.43494882, -63.43494882, -92.29061004,
-16.92751306, -99.09027692, -99.09027692, -16.92751306,
-99.09027692, -16.92751306, -9.86580694, -8.74616226,
-9.86580694, -8.74616226, -8.74616226, -2.20259816,
-2.20259816, -2.20259816, -9.86580694, -2.20259816,
-2.48955292, -2.48955292, -2.48955292, -2.48955292,
4.96974073, 4.96974073, 4.96974073, 4.96974073,
-2.48955292, -2.48955292, -2.48955292, -2.48955292,
-2.48955292, -9.86580694, -9.86580694, -9.86580694,
-16.92751306, -19.29004622, -19.29004622, -26.56505118,
-19.29004622, -19.29004622, -19.29004622, -19.29004622])
xx = np.linspace(-180, 180, 181)
scipy_kde = stats.gaussian_kde(baz)
print scipy_kde.integrate_box_1d(-180,180)
figure()
plot(xx, scipy_kde(xx), c='green')
baz[baz<0] += 360
xx = np.linspace(0, 360, 181)
scipy_kde = stats.gaussian_kde(baz)
print scipy_kde.integrate_box_1d(-180,180)
plot(xx, scipy_kde(xx), c='red') 回答 3
Stack Overflow用户
发布于 2017-10-23 18:21:20
下面是@kingjr更准确的答案的快速近似:
def vonmises_pdf(x, mu, kappa):
return np.exp(kappa * np.cos(x - mu)) / (2. * np.pi * scipy.special.i0(kappa))
def vonmises_fft_kde(data, kappa, n_bins):
bins = np.linspace(-np.pi, np.pi, n_bins + 1, endpoint=True)
hist_n, bin_edges = np.histogram(data, bins=bins)
bin_centers = np.mean([bin_edges[1:], bin_edges[:-1]], axis=0)
kernel = vonmises_pdf(
x=bin_centers,
mu=0,
kappa=kappa
)
kde = np.fft.fftshift(np.fft.irfft(np.fft.rfft(kernel) * np.fft.rfft(hist_n)))
kde /= np.trapz(kde, x=bin_centers)
return bin_centers, kdeTest (使用tqdm作为进度条和时间,使用matplotlib验证结果):
import numpy as np
from tqdm import tqdm
import scipy.stats
import matplotlib.pyplot as plt
n_runs = 1000
n_bins = 100
kappa = 10
for _ in tqdm(xrange(n_runs)):
bins1, kde1 = vonmises_kde(
data=np.r_[
np.random.vonmises(-1, 5, 1000),
np.random.vonmises(2, 10, 500),
np.random.vonmises(3, 20, 100)
],
kappa=kappa,
n_bins=n_bins
)
for _ in tqdm(xrange(n_runs)):
bins2, kde2 = vonmises_fft_kde(
data=np.r_[
np.random.vonmises(-1, 5, 1000),
np.random.vonmises(2, 10, 500),
np.random.vonmises(3, 20, 100)
],
kappa=kappa,
n_bins=n_bins
)
plt.figure()
plt.plot(bins1, kde1, label="kingjr's solution")
plt.plot(bins2, kde2, label="dolf's FFT solution")
plt.legend()
plt.show()结果:
100%|██████████| 1000/1000 [00:07<00:00, 135.29it/s]
100%|██████████| 1000/1000 [00:00<00:00, 1945.14it/s](1945 / 135 =快14倍)
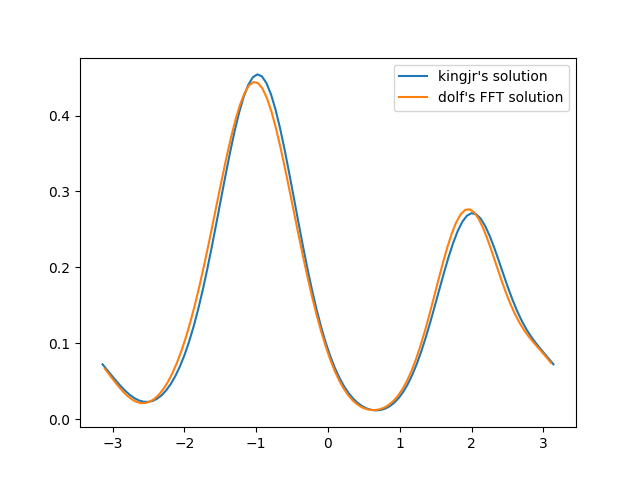
为了获得更高的速度,请使用整数幂2作为回收箱的数量。它的比例也更好(也就是说,它保持快速与许多回收箱和大量的数据)。在我的电脑上,它比n_bins=1024的最初答案快118倍。
为什么会起作用?
两个信号的FFTs的乘积(没有零填充)等于两个信号的圆形(或循环)卷积。核密度估计基本上是一个内核,在每个数据点的位置都有一个脉冲信号。
为什么不精确?
由于我使用直方图来均匀地空间数据,所以我失去了每个样本的准确位置,并且只使用它所属的垃圾箱的中心。每个垃圾箱中的样本数被用作该点上脉冲的大小。例如:暂时忽略标准化,如果您有一个0到1的bin,并且在这个容器中有两个样本,分别为0.1和0.2,那么exact KDE将是the kernel centred around 0.1 + the kernel centred around 0.2。近似为2x‘核中心在0.5附近,这是垃圾箱的中心。
Stack Overflow用户
发布于 2017-06-27 15:04:25
戴夫的答案是不正确的,因为scipy的vonmises并没有围绕着[-pi, pi]。
相反,您可以使用以下代码,这是基于相同的原则。它以numpy描述的方程为基础。
def vonmises_kde(data, kappa, n_bins=100):
from scipy.special import i0
bins = np.linspace(-np.pi, np.pi, n_bins)
x = np.linspace(-np.pi, np.pi, n_bins)
# integrate vonmises kernels
kde = np.exp(kappa*np.cos(x[:, None]-data[None, :])).sum(1)/(2*np.pi*i0(kappa))
kde /= np.trapz(kde, x=bins)
return bins, kde下面是一个例子
import matplotlib.pyplot as plt
import numpy as np
from numpy.random import vonmises
# generate complex circular distribution
data = np.r_[vonmises(-1, 5, 1000), vonmises(2, 10, 500), vonmises(3, 20, 100)]
# plot data histogram
fig, axes = plt.subplots(2, 1)
axes[0].hist(data, 100)
# plot kernel density estimates
x, kde = vonmises_kde(data, 20)
axes[1].plot(x, kde){kind=link}
Stack Overflow用户
发布于 2015-03-09 13:59:12
所以我认为这是一个合理的解决方案。基本上,我使用Von分布作为核密度估计的基函数。下面是代码,以防对其他人有用。
def vonmises_KDE(data, kappa, plot=None):
"""
Create a kernal densisity estimate of circular data using the von mises
distribution as the basis function.
"""
# imports
from scipy.stats import vonmises
from scipy.interpolate import interp1d
# convert to radians
data = np.radians(data)
# set limits for von mises
vonmises.a = -np.pi
vonmises.b = np.pi
x_data = np.linspace(-np.pi, np.pi, 100)
kernels = []
for d in data:
# Make the basis function as a von mises PDF
kernel = vonmises(kappa, loc=d)
kernel = kernel.pdf(x_data)
kernels.append(kernel)
if plot:
# For plotting
kernel /= kernel.max()
kernel *= .2
plt.plot(x_data, kernel, "grey", alpha=.5)
vonmises_kde = np.sum(kernels, axis=0)
vonmises_kde = vonmises_kde / np.trapz(vonmises_kde, x=x_data)
f = interp1d( x_data, vonmises_kde )
if plot:
plt.plot(x_data, vonmises_kde, c='red')
return x_data, vonmises_kde, f
baz = np.array([-92.29061004, -85.42607874, -85.42607874, -70.01689348,
-63.43494882, -63.43494882, -70.01689348, -70.01689348,
-59.93141718, -63.43494882, -59.93141718, -63.43494882,
-63.43494882, -63.43494882, -57.52880771, -53.61564818,
-57.52880771, -63.43494882, -63.43494882, -92.29061004,
-16.92751306, -99.09027692, -99.09027692, -16.92751306,
-99.09027692, -16.92751306, -9.86580694, -8.74616226,
-9.86580694, -8.74616226, -8.74616226, -2.20259816,
-2.20259816, -2.20259816, -9.86580694, -2.20259816,
-2.48955292, -2.48955292, -2.48955292, -2.48955292,
4.96974073, 4.96974073, 4.96974073, 4.96974073,
-2.48955292, -2.48955292, -2.48955292, -2.48955292,
-2.48955292, -9.86580694, -9.86580694, -9.86580694,
-16.92751306, -19.29004622, -19.29004622, -26.56505118,
-19.29004622, -19.29004622, -19.29004622, -19.29004622])
kappa = 12
x_data, vonmises_kde, f = vonmises_KDE(baz, kappa, plot=1)https://stackoverflow.com/questions/28839246
复制相似问题
腾讯云开发者
