
火花分区(Ing)如何处理HDFS中的文件?
我正在使用HDFS在集群上使用Apache。据我所知,HDFS正在数据节点上分发文件。因此,如果在文件系统上放置一个"file.txt“,那么它将被分割成分区。现在我给你打电话
rdd = SparkContext().textFile("hdfs://.../file.txt") 来自阿帕奇·斯帕克。rdd现在是否自动与文件系统上的"file.txt“分区相同?当我打电话时会发生什么
rdd.repartition(x)在哪里x>那么hdfs使用的分区?星火是否会在物理上重新安排hdfs的数据以在本地工作?
示例:我在HDFS-系统上放置了一个30 10的Textfile,该系统在10个节点上分发它。会使用同样的10个分区吗?当我调用重分区(1000)时,在集群中洗牌30 and?
回答 4
Stack Overflow用户
发布于 2015-03-12 14:16:05
当Spark从HDFS读取一个文件时,它会为单个输入分区创建一个分区。输入拆分由用于读取该文件的Hadoop InputFormat设置。例如,如果您使用textFile(),它将是Hadoop中的TextInputFormat,它将为HDFS的单个块返回一个分区(但分区之间的分割将在在线拆分中完成,而不是确切的块拆分),除非您有一个压缩的文本文件。在压缩文件的情况下,您将得到单个文件的单个分区(因为压缩的文本文件是不可分割的)。
当您调用rdd.repartition(x)时,它将执行从rdd中的N分区到您希望拥有的x分区的数据洗牌,分区将在循环的基础上完成。
如果在HDFS上存储了一个30 in的未压缩文本文件,那么使用默认的HDFS块大小设置(128 In),它将存储在235个块中,这意味着从该文件读取的RDD将有235个分区。当您调用repartition(1000)时,您的RDD将被标记为要重新分区,但实际上,只有在此RDD (延迟执行概念)之上执行一个操作时,它才会被洗牌到1000个分区。
Stack Overflow用户
发布于 2018-12-12 21:31:36
当使用spark读取非桶式HDFS文件(例如parquet)时,DataFrame分区df.rdd.getNumPartitions的数量取决于以下因素:
spark.default.parallelism(大致转换为应用程序可用的#核)spark.sql.files.maxPartitionBytes(默认128)spark.sql.files.openCostInBytes(默认为4MB)
对分区数量的粗略估计是:
- 如果有足够的内核并行读取所有数据(也就是说,每128 at数据至少有一个核心)
AveragePartitionSize ≈ min(4MB, TotalDataSize/#cores) NumberOfPartitions ≈ TotalDataSize/AveragePartitionSize - 如果你没有足够的核心,
AveragePartitionSize ≈ 128MB NumberOfPartitions ≈ TotalDataSize/AveragePartitionSize
精确的计算有点复杂,可以在FileSourceScanExec的代码基上找到,请参阅这里。
Stack Overflow用户
发布于 2017-08-16 05:52:59
以下是“如何将HDFS中的块作为分区加载到火花工作人员中”的快照
在这张图中,4个HDFS块作为火花分区加载到3个工作内存中。
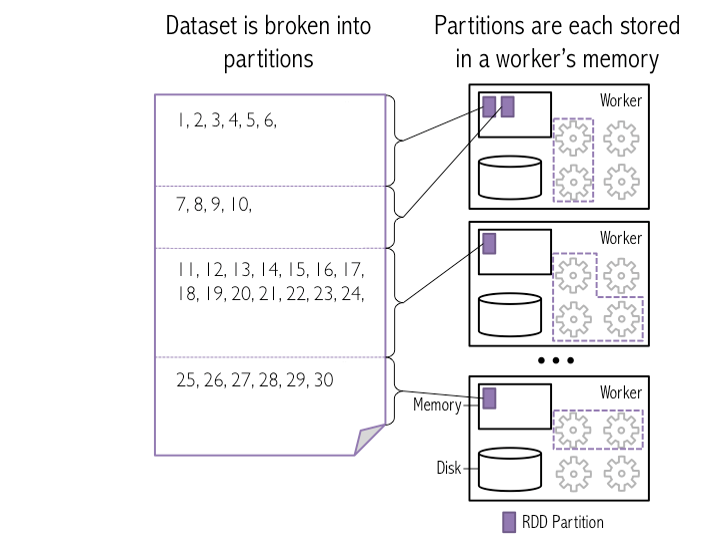
示例:我在HDFS-系统上放置了一个30 10的Textfile,该系统在10个节点上分发它。 威尔·斯帕克 ( a)使用相同的10个分区? 火花加载相同的10个HDFS bocks到工人内存作为分区。我假设30 GB文件的块大小应该是3 GB,以便在调用重新分区(1000)?时获得10个分区/块(在默认情况下) b)洗牌30 GB。 是,在工作节点之间混合数据,以便在工作内存中创建1000个分区。
注意:
HDFS Block -> Spark partition : One block can represent as One partition (by default)
Spark partition -> Workers : Many/One partitions can present in One workers https://stackoverflow.com/questions/29011574
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号