
Hibernate SQL In子句使CPU使用率达到100%
在我的java应用程序中,我使用的是SQL server and Hibernate3 with EJB。当我尝试执行select查询with In clause时,DB服务器CPU使用率达到100%。但是当我试图在SQL management studio中运行相同的查询时,该查询是在没有任何CPU峰值的情况下运行的。应用服务器和DB服务器是两台不同的机器。我的表有以下模式,
CREATE TABLE student_table (
Student_Id BIGINT NOT NULL IDENTITY
, Class_Id BIGINT NOT NULL
, Student_First_Name VARCHAR(100) NOT NULL
, Student_Last_Name VARCHAR(100)
, Roll_No VARCHAR(100) NOT NULL
, PRIMARY KEY (Student_Id)
, CONSTRAINT UK_StudentUnique_1 UNIQUE (Class_Id, Roll_No)
);该表包含大约1000 K的记录。我的疑问是
select Student_Id from student_table where Roll_No in ('A101','A102','A103',.....'A250');In子句包含250个值,当我试图在中运行上述查询时,结果将在1秒内检索,并且没有任何CPU峰值。但是,当我试图通过hibernate运行相同的查询时,CPU峰值在60秒左右达到100%,结果大约被检索到60秒。hibernate查询是,
Criteria studentCriteria = session.createCriteria(StudentTO.class);
studentCriteria.add(Restrictions.in("rollNo", rollNoLists)); //rollNoLists is an Arraylist contains 250 Strings
studentCriteria.setProjection(Projections.projectionList().add(Projections.property("studentId")));
List<Long> studentIds = new ArrayList<Long>();
List<Long> results = (ArrayList<Long>) studentCriteria.list();
if (results != null && results.size() > 0) {
studentIds.addAll(results);
}
return studentIds;为什么会这样呢?如果在management中运行相同的查询,结果将在没有任何尖峰的情况下检索,并在1秒内检索结果。有什么解决办法吗?
Edit1:我的hibernate生成的查询是
select this_.Student_Id as y0_ from student_table this_ where this_.Roll_No in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)Edit2:我的执行计划--这是在索引roll_no之后
CREATE INDEX i_student_roll_no ON student_table (Roll_No)
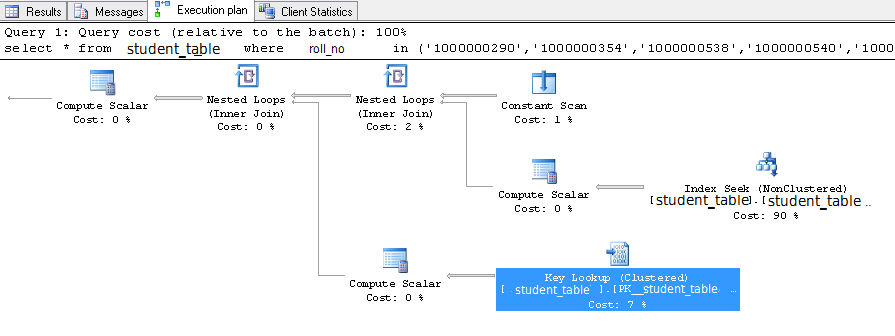
,
Stack Overflow用户
发布于 2015-05-05 03:58:09
我只是为你指出LBushkin的这一部分答案,来自这个职位
第二,当使用IN或or和可变数量的参数时,您将导致数据库必须在每次参数更改时重新解析查询并重新构建执行计划。构建查询的执行计划可能是一个昂贵的步骤。大多数数据库缓存它们运行的查询的执行计划,使用精确的查询文本作为键。如果执行类似的查询,但谓词中有不同的参数值,则很可能导致数据库花费大量时间解析和构建执行计划。这就是为什么强烈推荐绑定变量作为确保最佳查询性能的一种方法。
因此,您可以尝试绑定变量以防止每次运行执行计划。
https://stackoverflow.com/questions/29814090
复制相似问题
腾讯云开发者
