
如何在scikit中使用SGDRegressor -学习
如何在scikit中使用SGDRegressor -学习
提问于 2015-05-22 02:20:30
我正在努力弄清楚如何正确地使用科学学习的SGDRegressor模型。为了适应数据集,我需要调用一个function fit(X,y),其中x是一个numpy形状数组( n_samples,n_features),y是长度n_samples的一维numpy数组。我想弄清楚y应该代表什么。
例如,我的数据如下所示:
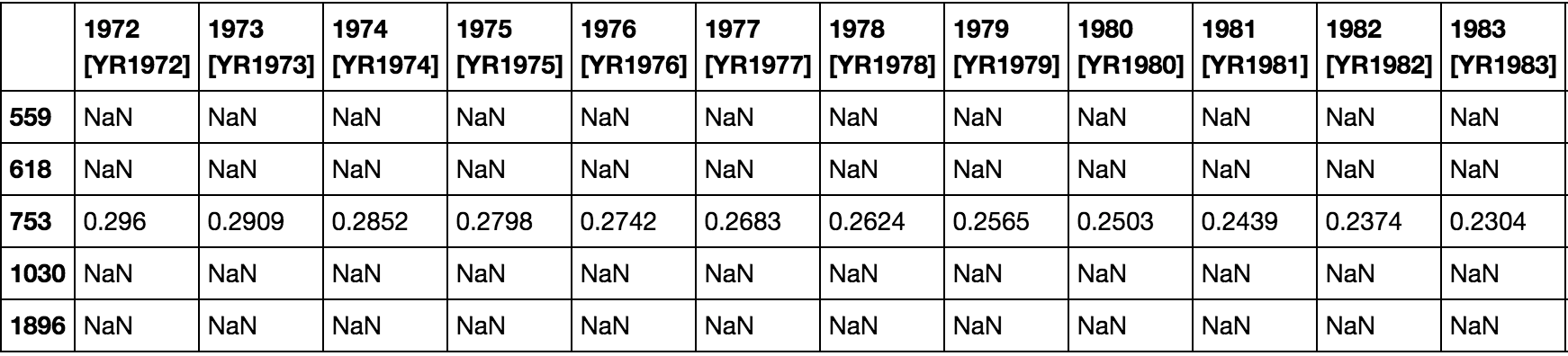
我的特征是1972年开始的年份,而值是该年的相应值。我正试图预测未来数年的价值,比如2008年或2012年。我假设数据中的每一行代表X中的行/示例,其中的每个元素都是一年的值。那样的话,你会是什么呢?我在想,y应该只是年数,但是y的长度应该是n_features,而不是n_samples。如果y的长度是n_samples,那么y可能是长度5的(下面显示的数据中的样本数)。我想我必须用某种方式来转换这些数据。
回答 2
Stack Overflow用户
发布于 2015-05-22 07:18:11
在机器学习中,y表示数据的标签或目标。也就是说,您的培训数据(X)的正确答案。
如果您想学习一些与年份相对应的值,那么这些年将是您的培训数据(X),而与它们关联的正确值将是您的目标(y)。
您可以注意到,这符合您在第一段中提到的大小:X的形状是(n_samples, n_features),因为它的条目数量和年份一样多,而且每个条目的大小都是1(只有一个特性,即年份),而y的长度是n_samples,因为您有一个与每年相关联的值。
Stack Overflow用户
发布于 2015-05-22 13:07:43
y是您的目标(您想要预测的内容),您可以这样得到它:
from sklearn import linear_model
clf = linear_model.SGDRegressor()
clf.fit(x_to_train, y_to_train)
# clf is a trained model
y_predicted = clf.predict(X_to_predict)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/30387365
复制相关文章
相似问题
腾讯云开发者
