
Oracle中的空白和孤岛解决方案-递归的使用
在Oracle中使用curser可以很容易地解决我的问题。但是,我想知道这是否可以只使用select。我有一个数据集,它包含以下字段: Start、Description、MaximumRow、SequentialOrder。
数据集由Description、Start、SequentialOrder排序。这是为说明目的而提供的数据:
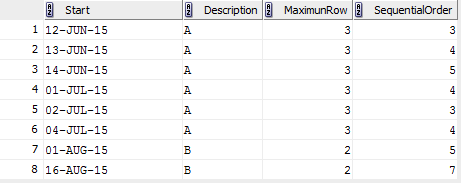
我想在一个不同的数据集(开始、结束、描述)中得到以下结果,其中Start是集合中"Start“字段的最小值,End是集合中"Start”字段的最大值。集合由以下规则定义:新集中的行总数不超过上一组中定义的最大行数,并且新集中的所有行都由SequentialOrder排序。
根据上述规则,我有以下几组:
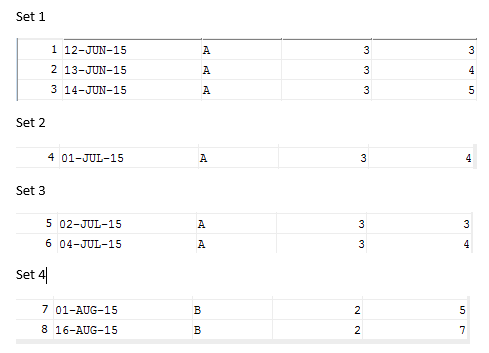
因此,我希望基于这个例子看到的结果是
12-Jun-15, 14-Jun-15, A
01-Jul-15, 01-Jul-15, A
02-Jul-15, 04-Jul-15, A
01-Aug-15, 16-Aug-15, B如果可以的话,请告知。我知道我们可以根据描述进行分组,但我不知道是否可以基于MaximumRow和SequentialOrder进行进一步的分组:如上所述,要计算的子集中的总行不能超过MaximumRow,必须按照SequentialOrder排序。
我不认为不使用游标就能做到这一点,但我还是会问,以防万一。
我附上了生成上面示例的脚本:
CREATE TABLE "TEST"
( "Start" DATE,
"Description" VARCHAR2(20 BYTE),
"MaximunRow" NUMBER,
"SequentialOrder" NUMBER
)
SET DEFINE OFF;
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('12-JUN-15','DD-MON-RR'),'A',3,3);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('13-JUN-15','DD-MON-RR'),'A',3,4);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('14-JUN-15','DD-MON-RR'),'A',3,5);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('01-JUL-15','DD-MON-RR'),'A',3,4);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('02-JUL-15','DD-MON-RR'),'A',3,3);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('04-JUL-15','DD-MON-RR'),'A',3,4);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('01-AUG-15','DD-MON-RR'),'B',2,5);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('16-AUG-15','DD-MON-RR'),'B',2,7);回答 1
Stack Overflow用户
发布于 2015-06-12 14:59:02
这是一个空隙和岛屿问题的变化,增加了每个岛的最大行数的复杂性。这有点长,但是您可以从识别由序列顺序引起的组开始:
select t.*,
row_number() over (partition by "Description" order by "Start") as rn,
case when lag("SequentialOrder")
over (partition by "Description" order by "Start") < "SequentialOrder"
then 1 else 0 end as newblock
from test t
order by "Start";
Start Description MaximunRow SequentialOrder RN NEWBLOCK
--------- ----------- ---------- --------------- --- ----------
12-JUN-15 A 3 3 1 0
13-JUN-15 A 3 4 2 1
14-JUN-15 A 3 5 3 1
01-JUL-15 A 3 4 4 0
02-JUL-15 A 3 3 5 0
04-JUL-15 A 3 4 6 1
01-AUG-15 B 2 5 1 0
16-AUG-15 B 2 7 2 1然后,您可以在以下基础上使用递归CTE (从11 gR2开始):
with u as (
select t.*,
row_number() over (partition by "Description" order by "Start") as rn,
case when lag("SequentialOrder")
over (partition by "Description" order by "Start") < "SequentialOrder"
then 1 else 0 end as newblock
from test t
),
r ("Start", "Description", "MaximunRow", "SequentialOrder", rn, blocknum,
pos, lastmaxrow) as (
select u."Start", u."Description", u."MaximunRow", u."SequentialOrder", u.rn,
1, 1, u."MaximunRow"
from u
where rn = 1
union all
select u."Start", u."Description", u."MaximunRow", u."SequentialOrder", u.rn,
case when r.pos = r.lastmaxrow or u.newblock = 0
then r.blocknum + 1 else r.blocknum end,
case when r.pos = r.lastmaxrow or u.newblock = 0
then 1 else r.pos + 1 end,
case when r.pos = r.lastmaxrow or u.newblock = 0
then r.lastmaxrow else u."MaximunRow" end
from r
join u on u."Description" = r."Description" and u.rn = r.rn + 1
)
select * from r
order by "Start";
Start Description MaximunRow SequentialOrder RN BLOCKNUM POS LASTMAXROW
--------- ----------- ---------- --------------- --- ---------- ---- ----------
12-JUN-15 A 3 3 1 1 1 3
13-JUN-15 A 3 4 2 1 2 3
14-JUN-15 A 3 5 3 1 3 3
01-JUL-15 A 3 4 4 2 1 3
02-JUL-15 A 3 3 5 3 1 3
04-JUL-15 A 3 4 6 3 2 3
01-AUG-15 B 2 5 1 1 1 2
16-AUG-15 B 2 7 2 1 2 2这是为每一行分配一个blocknum,从锚成员中每个描述的一个开始,如果newblock为零(指示序列中断)或块中的成员数是前一个最大值,则在递归成员中递增。(我可能没有“前一个最大值”的逻辑,因为问题还不清楚。)
然后,您可以按照描述和生成的块号进行分组:
with u as (
select t.*,
row_number() over (partition by "Description" order by "Start") as rn,
case when lag("SequentialOrder")
over (partition by "Description" order by "Start") < "SequentialOrder"
then 1 else 0 end as newblock
from test t
),
r ("Start", "Description", "MaximunRow", "SequentialOrder", rn, blocknum,
pos, lastmaxrow) as (
select u."Start", u."Description", u."MaximunRow", u."SequentialOrder", u.rn,
1, 1, u."MaximunRow"
from u
where rn = 1
union all
select u."Start", u."Description", u."MaximunRow", u."SequentialOrder", u.rn,
case when r.pos = r.lastmaxrow or u.newblock = 0
then r.blocknum + 1 else r.blocknum end,
case when r.pos = r.lastmaxrow or u.newblock = 0
then 1 else r.pos + 1 end,
case when r.pos = r.lastmaxrow or u.newblock = 0
then r.lastmaxrow else u."MaximunRow" end
from r
join u on u."Description" = r."Description" and u.rn = r.rn + 1
)
select min(r."Start") as "Start", max(r."Start") as "End", r."Description"
from r
group by r."Description", r.blocknum
order by r."Description", r.blocknum;
Start End Description
--------- --------- -----------
12-JUN-15 14-JUN-15 A
01-JUL-15 01-JUL-15 A
02-JUL-15 04-JUL-15 A
01-AUG-15 16-AUG-15 B 您的示例数据不会触发最大行中断,因为您的任何序列都不会超过3。有了一些额外的数据:
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('15-JUN-15','DD-MON-RR'),'A',3,7);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('16-JUN-15','DD-MON-RR'),'A',3,8);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('17-JUN-15','DD-MON-RR'),'A',3,10);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('18-JUN-15','DD-MON-RR'),'A',3,12);
Insert into TEST ("Start","Description","MaximunRow","SequentialOrder") values (to_date('19-JUN-15','DD-MON-RR'),'A',3,13);相同的查询得到:
Start End Description
--------- --------- -----------
12-JUN-15 14-JUN-15 A
15-JUN-15 17-JUN-15 A
18-JUN-15 19-JUN-15 A
01-JUL-15 01-JUL-15 A
02-JUL-15 04-JUL-15 A
01-AUG-15 16-AUG-15 B 所以你可以看到,它是分裂的,在序列的变化和击中三行在块。
演示。
通过直接比较case语句中的顺序(而不是使用newblock),您可以只使用递归的CTE,而不是前面的中间命令;但是,让rn查找下一行要比尝试查找下一个日期要容易,因为它们并不是连续的。
https://stackoverflow.com/questions/30803021
复制相似问题
腾讯云开发者
