
Scrapy ` `ReactorNotRestartable`:运行两个(或多个)蜘蛛的一个类
Scrapy ` `ReactorNotRestartable`:运行两个(或多个)蜘蛛的一个类
提问于 2015-06-21 23:46:20
我正在用Scrapy两阶段爬行来聚合日常数据。第一阶段从索引页面生成URL列表,第二阶段为列表中的每个URL编写HTML到Kafka主题。
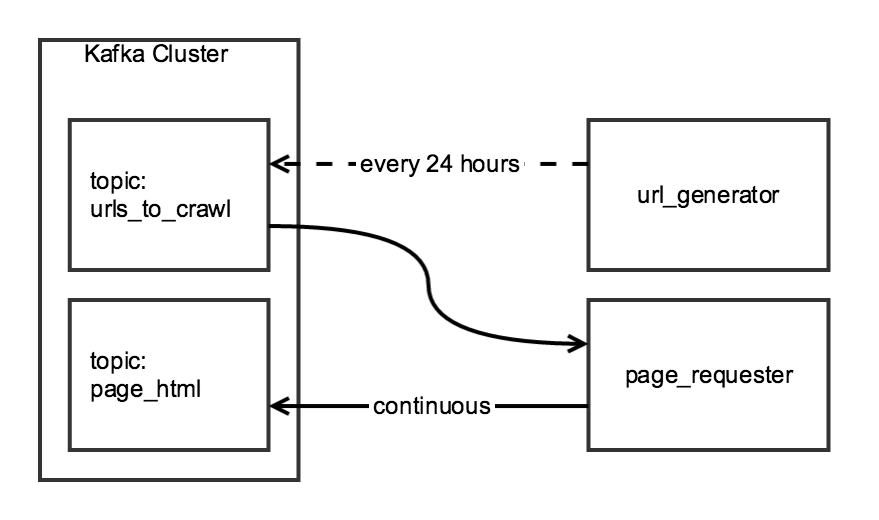
尽管爬行的两个组件是相关的,但我希望它们是独立的:url_generator将作为预定任务每天运行一次,page_requester将持续运行,在可用时处理URL。为了“礼貌”,我将调整DOWNLOAD_DELAY,使爬虫在24小时内很好地完成,但把最小的负荷在网站上。
我创建了一个CrawlerRunner类,它具有生成URL和检索HTML的函数:
from twisted.internet import reactor
from scrapy.crawler import Crawler
from scrapy import log, signals
from scrapy_somesite.spiders.create_urls_spider import CreateSomeSiteUrlList
from scrapy_somesite.spiders.crawl_urls_spider import SomeSiteRetrievePages
from scrapy.utils.project import get_project_settings
import os
import sys
class CrawlerRunner:
def __init__(self):
sys.path.append(os.path.join(os.path.curdir, "crawl/somesite"))
os.environ['SCRAPY_SETTINGS_MODULE'] = 'scrapy_somesite.settings'
self.settings = get_project_settings()
log.start()
def create_urls(self):
spider = CreateSomeSiteUrlList()
crawler_create_urls = Crawler(self.settings)
crawler_create_urls.signals.connect(reactor.stop, signal=signals.spider_closed)
crawler_create_urls.configure()
crawler_create_urls.crawl(spider)
crawler_create_urls.start()
reactor.run()
def crawl_urls(self):
spider = SomeSiteRetrievePages()
crawler_crawl_urls = Crawler(self.settings)
crawler_crawl_urls.signals.connect(reactor.stop, signal=signals.spider_closed)
crawler_crawl_urls.configure()
crawler_crawl_urls.crawl(spider)
crawler_crawl_urls.start()
reactor.run()当我实例化类时,我能够成功地单独执行任何一个函数,但不幸的是,我无法一起执行它们:
from crawl.somesite import crawler_runner
cr = crawler_runner.CrawlerRunner()
cr.create_urls()
cr.crawl_urls()第二个函数调用在尝试在twisted.internet.error.ReactorNotRestartable函数中执行reactor.run()时生成一个crawl_urls。
我想知道这个代码是否有一个简单的修复方法(例如运行两个单独的Twisted反应堆的方法),或者是否有更好的方法来构建这个项目。
Stack Overflow用户
回答已采纳
发布于 2015-07-05 18:07:17
在一个反应堆内运行多个蜘蛛是可能的,方法是保持反应堆打开,直到所有蜘蛛停止运行。这是通过保留所有正在运行的蜘蛛的列表而在此列表为空之前不执行reactor.stop()来实现的:
import sys
import os
from scrapy.utils.project import get_project_settings
from scrapy_somesite.spiders.create_urls_spider import Spider1
from scrapy_somesite.spiders.crawl_urls_spider import Spider2
from scrapy import signals, log
from twisted.internet import reactor
from scrapy.crawler import Crawler
class CrawlRunner:
def __init__(self):
self.running_crawlers = []
def spider_closing(self, spider):
log.msg("Spider closed: %s" % spider, level=log.INFO)
self.running_crawlers.remove(spider)
if not self.running_crawlers:
reactor.stop()
def run(self):
sys.path.append(os.path.join(os.path.curdir, "crawl/somesite"))
os.environ['SCRAPY_SETTINGS_MODULE'] = 'scrapy_somesite.settings'
settings = get_project_settings()
log.start(loglevel=log.DEBUG)
to_crawl = [Spider1, Spider2]
for spider in to_crawl:
crawler = Crawler(settings)
crawler_obj = spider()
self.running_crawlers.append(crawler_obj)
crawler.signals.connect(self.spider_closing, signal=signals.spider_closed)
crawler.configure()
crawler.crawl(crawler_obj)
crawler.start()
reactor.run()类被执行:
from crawl.somesite.crawl import CrawlRunner
cr = CrawlRunner()
cr.run()此解决方案基于Kiran Koduru的博客。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/30970436
复制相关文章
相似问题
腾讯云开发者
