
学习LogisticRegression和更改分类的默认阈值
我正在使用LogisticRegression从学习包,并有一个关于分类的快速问题。我为我的分类器建立了一个ROC曲线,结果是我的训练数据的最佳阈值在0.25左右。我假设创建预测时的默认阈值是0.5。在进行10倍交叉验证时,如何更改此默认设置,以了解模型中的准确性?基本上,我想让我的模型预测大于0.25,而不是0.5的人的“1”。我已经翻阅了所有的文档,似乎什么也找不到。
回答 7
Stack Overflow用户
发布于 2015-07-14 21:42:31
这不是一个内置的功能。您可以“添加”它,方法是将LogisticRegression类包装在自己的类中,并添加在自定义predict()方法中使用的threshold属性。
然而,有些人警告说:
- 默认阈值实际上是0。
LogisticRegression.decision_function()返回到选定的分离超平面的有符号距离。如果您查看的是predict_proba(),那么您将看到超平面距离的logit(),阈值为0.5。但计算起来要昂贵得多。 - 通过选择像这样的“最优”阈值,您正在利用信息后学习,这破坏了您的测试集(即,您的测试或验证集不再提供对样本外错误的无偏见估计)。因此,您可能会导致额外的过度拟合,除非您只选择了一个交叉验证循环内的阈值,然后使用它和您的测试集的训练分类器。
- 考虑使用
class_weight,如果您有一个不平衡的问题,而不是手动设置阈值。这将迫使分类器选择远离感兴趣类的超平面。
Stack Overflow用户
发布于 2018-09-10 08:12:53
我想给出一个实际的答案。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, recall_score, roc_auc_score, precision_score
import numpy as np
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_features=20, n_samples=1000, random_state=10
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
clf = LogisticRegression(class_weight="balanced")
clf.fit(X_train, y_train)
THRESHOLD = 0.25
preds = np.where(clf.predict_proba(X_test)[:,1] > THRESHOLD, 1, 0)
pd.DataFrame(data=[accuracy_score(y_test, preds), recall_score(y_test, preds),
precision_score(y_test, preds), roc_auc_score(y_test, preds)],
index=["accuracy", "recall", "precision", "roc_auc_score"])通过将THRESHOLD改为0.25,人们可以发现recall和precision的分数正在下降。但是,通过删除class_weight参数,accuracy增加了,但recall得分下降了。请参阅@已接受的答案
Stack Overflow用户
发布于 2020-05-06 20:21:09
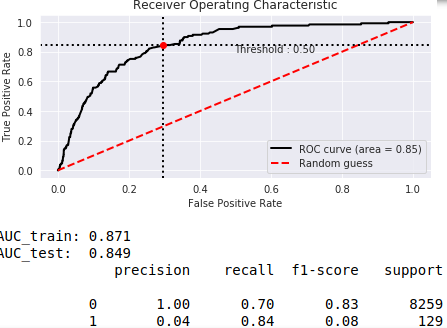
你可以改变阈值,但它是0.5,所以计算是正确的。如果您有一个不平衡的集合,分类如下所示。
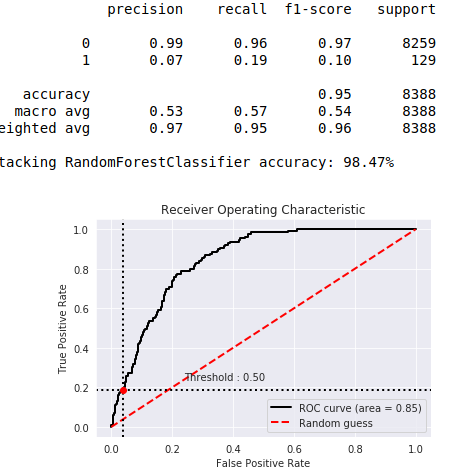
你可以看到,第一类是非常缺乏预期的。1级占人口的2%。在平衡结果变量50%到50% (使用过采样)后,0.5阈值到达图表的中心。
https://stackoverflow.com/questions/31417487
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号