
DocumentDb无法处理列名中的连字符(-)
我将以下XML保存到DocumentDB中:
<DocumentDbTest_Countries>
<country>C25103657983</country>
<language>C25103657983</language>
<countryCode>383388823</countryCode>
<version>2015-08-25T08:36:59:982.3552</version>
<integrity>
<hash-algorithm>sha1</hash-algorithm>
<hash />
</integrity>
<context-info>
<created-by>unittestuser</created-by>
<created-on>2015/08/25 08:36:59</created-on>
<created-time-zone>UTC</created-time-zone>
<modified-by>unittestuser</modified-by>
<modified-on>2015/08/25 08:36:59</modified-on>
<modified-time-zone>UTC</modified-time-zone>
</context-info>
</DocumentDbTest_Countries>它可以很好地保存到DocumentDB,如下所示:
{
"DocumentDbTest_Countries": {
"integrity": {
"hash-algorithm": "sha1",
"hash": ""
},
"context-info": {
"created-by": "unittestuser",
"created-on": "2015/08/25 08:36:59",
"created-time-zone": "UTC",
"modified-by": "unittestuser",
"modified-on": "2015/08/25 08:36:59",
"modified-time-zone": "UTC"
},
"country": "C25103657983",
"language": "C25103657983",
"countryCode": 383388823,
"version": "2015-08-25T08:36:59:982.3552"
},
"id": "f917945d-eaee-4eff-944d-dae366de7be1"
}如您所见,列名实际上是在DocumentDB中用连字符(-)保存的(显然没有任何错误/异常/警告),但是当我试图进行查找时,它在查询资源管理器中失败。似乎没有办法搜索连字符的列名。这是真的吗?还是,我漏掉了什么?有人能告诉我关于这个限制的文件吗??
回答 3
Stack Overflow用户
发布于 2015-08-26 08:50:48
诀窍是使用CollectionName.DocumentName,而不是只使用DocumentName,像这样(感谢@Laan为我指出了这个方向) :):
SELECT * FROM TestProject.DocumentDbTest_Countries c where c["@country"] = "C26092630539"
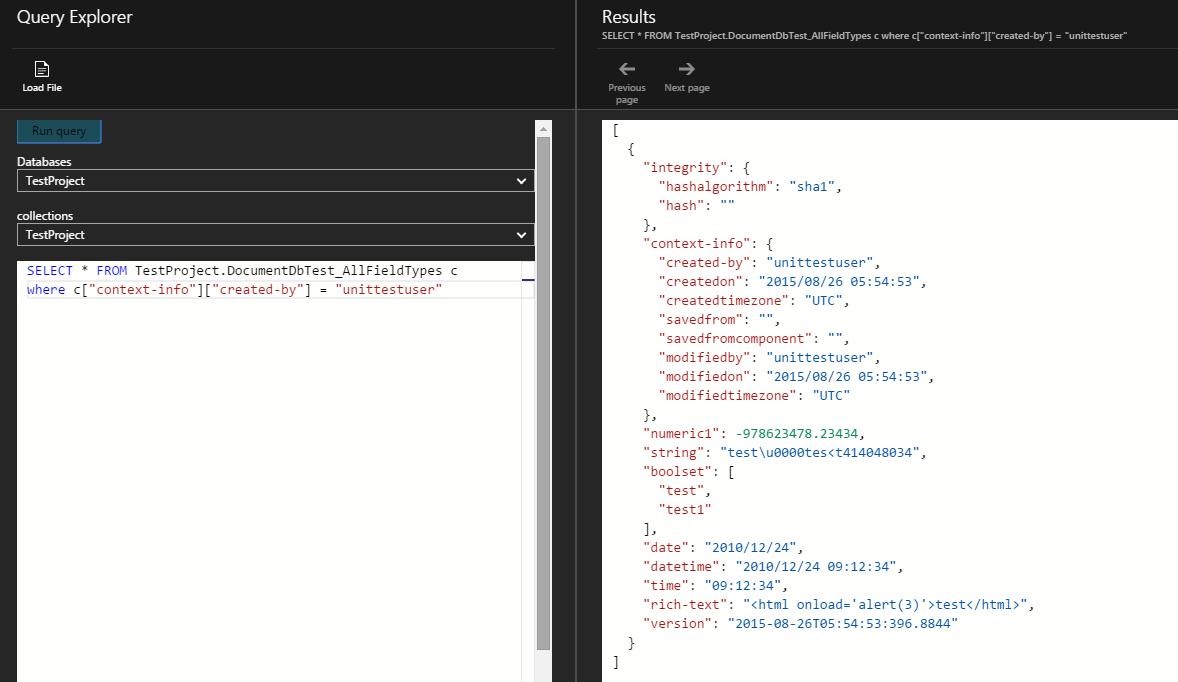
但是,我仍然忽略了返回文档数据中的Document.Id和Document.SelfLink数据。
Stack Overflow用户
发布于 2015-08-25 16:30:20
用于使用特定字符(空格、"@“、"-”等)的字段名。或者哪一个与SQL关键字冲突,您必须使用引用的属性访问器语法。因此,与其写:
SELECT * FROM c WHERE c.context-info.created-by = "unittestuser"写:
SELECT * FROM c WHERE c["context-info"]["created-by"] = "unittestuser"Stack Overflow用户
发布于 2015-08-25 09:31:35
还可以使用引用的属性运算符[]访问属性。例如,选择c.grade并选择c"grade“是等效的。当您需要转义包含空格、特殊字符或碰巧与SQL关键字或保留词同名的属性时,此语法非常有用。
-是这些特殊字符之一,因此要访问包含-的属性,需要使用引用的属性运算符。已记录在案:)
当然,惯用的方法是使用骆驼套管而不是连字符,但是如果你不想改变你的结构,你需要使用引用的属性。
例如,使用测试数据,此查询工作:
SELECT c["country-code"] FROM root.DocumentDbTest_Countries c编辑:
查询的语法有点混乱,这就是导致大多数问题的原因。与你想的相反,
select * from DocumentDbTest_Countries实际上并不意味着“把DocumentDbTest_Countries中的所有数据都给我”。相反,它似乎意味着“获取当前集合中的所有数据,并将其别名为DocumentDbTest_Countries”。当您查看返回的数据时,这是很明显的--您希望它只返回DocumentDbTest_Countries中的字段,但是它实际上返回所有的值,包括id (它不是DocumentDbTest_Countries的一部分),应该在前面是显而易见的:D)。
我不明白为什么它是这样设计的(即使使用DocumentDbTest_Countries c显式指定别名也不选择DocumentDbTest_Countries),但修复方法实际上是使用集合名启动标识符。root只是指“这个集合”的一种方式,所以
select * from root.DocumentDbTest_Countries返回您对原始查询的期望。除非您了解原始查询的行为方式,否则我会坚持每次都显式地使用root (或集合名称)作为根。在我看来,使用from whatever总是会返回当前的集合,除非您有一个名为whatever的集合--如果您问我,这是一个奇怪的设计决策。这意味着除非您有一个名为lotsOfFun的集合,否则以下操作与使用root相同
select * from lotsOfFun.DocumentDbTest_Countries也许是因为顶层的对象没有命名,所以他们决定不管什么名字都行,但这只是一个想法。
https://stackoverflow.com/questions/32199469
复制相似问题
腾讯云开发者
