
多线程只比.4快一秒钟?
因此,对于我的编程类,我们必须执行以下操作:
- 用从0到9的五百万整数来填充整数数组.
- 然后找出每个数字(0-9)发生的次数,并显示如下。
我们必须测量计算单线程和多线程发生所需的时间。目前,我的8核心cpu上平均有9.3ms的多线程线程,8.9ms的多线程线程,这是为什么呢?
目前,对于多线程,我有一个充满数字的数组,并且正在计算每个线程要计数的下界和上界。以下是我目前的尝试:
public void createThreads(int divisionSize) throws InterruptedException {
threads = new Thread[threadCount];
for(int i = 0; i < threads.length; i++) {
final int lower = (i*divisionSize);
final int upper = lower + divisionSize - 1;
threads[i] = new Thread(new Runnable() {
long start, end;
@Override
public void run() {
start = System.nanoTime();
for(int i = lower; i <= upper; i++) {
occurences[numbers[i]]++;
}
end = System.nanoTime();
milliseconds += (end-start)/1000000.0;
}
});
threads[i].start();
threads[i].join();
}
}有人能给点线索吗?干杯。
回答 4
Stack Overflow用户
发布于 2015-10-22 08:31:43
您实际上是按顺序执行所有工作,因为您创建的每个线程都会立即join它。
将主构造循环外的threads[i].join()移动到它自己的循环中。在创建线程时,您可能还应该启动循环之外的所有线程,因为在仍在创建新线程时启动它们并不是一个好主意,因为创建线程需要时间。
class ThreadTester {
private final int threadCount;
private final int numberCount;
int[] numbers = new int[5_000_000];
AtomicIntegerArray occurences;
Thread[] threads;
AtomicLong milliseconds = new AtomicLong();
public ThreadTester(int threadCount, int numberCount) {
this.threadCount = threadCount;
this.numberCount = numberCount;
occurences = new AtomicIntegerArray(numberCount);
threads = new Thread[threadCount];
Random r = new Random();
for (int i = 0; i < numbers.length; i++) {
numbers[i] = r.nextInt(numberCount);
}
}
public void createThreads() throws InterruptedException {
final int divisionSize = numbers.length / threadCount;
for (int i = 0; i < threads.length; i++) {
final int lower = (i * divisionSize);
final int upper = lower + divisionSize - 1;
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
long start = System.nanoTime();
for (int i = lower; i <= upper; i++) {
occurences.addAndGet(numbers[i], 1);
}
long end = System.nanoTime();
milliseconds.addAndGet(end - start);
}
});
}
}
private void startThreads() {
for (Thread thread : threads) {
thread.start();
}
}
private void finishThreads() throws InterruptedException {
for (Thread thread : threads) {
thread.join();
}
}
public long test() throws InterruptedException {
createThreads();
startThreads();
finishThreads();
return milliseconds.get();
}
}
public void test() throws InterruptedException {
for (int threads = 1; threads < 50; threads++) {
ThreadTester tester = new ThreadTester(threads, 10);
System.out.println("Threads=" + threads + " ns=" + tester.test());
}
}请注意,即使在这里,最快的解决方案是使用一个线程,但您可以清楚地看到,偶数线程的执行速度更快,因为我使用的是一个i5,它有两个核心,但通过超线程作为4工作。
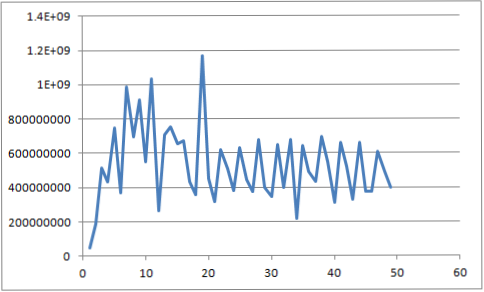
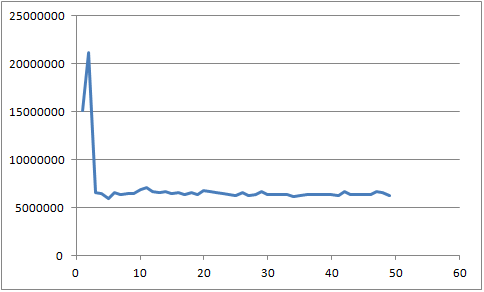
但有趣的是--正如@biziclop所建议的--通过occurrences消除线程之间的所有争用,为每个线程赋予自己的“出现”数组,我们得到了一个更预期的结果:
Stack Overflow用户
发布于 2015-10-22 09:00:48
其他答案都探讨了您的代码的直接问题,我将给您一个不同的角度:一个是关于多线程的一般设计。
并行计算加速计算的想法取决于这样一种假设,即将问题分解成的小位实际上可以并行运行,彼此独立。
乍一看,你的问题就像这样,把输入范围切成8个等份,启动8个线程,然后关闭它们。
不过,有一个陷阱:
occurences[numbers[i]]++;occurences数组是所有线程共享的资源,因此您必须控制对它的访问以确保正确性:显式同步(这是慢的)或类似于AtomicIntegerArray的东西。但是,只有当对Atomic*类的访问很少有争议时,它们才是真正快速的。在这种情况下,访问将受到很大的争议,因为您的内部循环所做的大部分工作都是在增加出现的次数。
,那么你能做什么?
造成这个问题的部分原因是,occurences是一个如此小的结构(一个只包含10个元素的数组,无论输入大小如何),线程将不断尝试更新相同的元素。但是你可以把它变成你的优势:让所有的线程保持它们自己的独立计数,当它们都完成时,只需要把它们的结果相加。这将增加一个小的,持续的开销,以结束的过程,但将使计算真正并行。
Stack Overflow用户
发布于 2015-10-22 08:32:14
join方法允许一个线程等待另一个线程的完成,因此第二个线程只在第一个线程完成之后才会启动。
启动所有线程后,加入每个线程。
public void createThreads(int divisionSize) throws InterruptedException {
threads = new Thread[threadCount];
for(int i = 0; i < threads.length; i++) {
final int lower = (i*divisionSize);
final int upper = lower + divisionSize - 1;
threads[i] = new Thread(new Runnable() {
long start, end;
@Override
public void run() {
start = System.nanoTime();
for(int i = lower; i <= upper; i++) {
occurences[numbers[i]]++;
}
end = System.nanoTime();
milliseconds += (end-start)/1000000.0;
}
});
threads[i].start();
}
for(int i = 0; i < threads.length; i++) {
threads[i].join();
}
}而且,在occurences[numbersi]++的代码中似乎存在竞争条件,所以很可能,如果您更新代码并使用更多的线程,输出就会不正确。您应该使用AtomicIntegerArray:https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/atomic/AtomicIntegerArray.html
https://stackoverflow.com/questions/33276516
复制相似问题
腾讯云开发者
