
如何优化这个neo4j查询?
如何优化这个neo4j查询?
提问于 2015-11-11 18:10:59
该查询用于从Grouplens数据集加载100万评等。我已经为用户和电影创建了节点,现在正在将它们合并到与电影的关系中。
load csv from "file:///ratings.csv" as row fieldterminator ';'
MERGE (u:User {userID:toInt(row[0])} )
MERGE (m:Movie {movieID:toInt(row[1])} )
MERGE (u)-[r:RATING {value:toInt(row[3])} ]->(m)当在JVM (膝上型计算机,4GB RAM)中分配2GB RAM时,这个查询需要很长时间,尽管在4-6 GB RAM (桌面)中运行得相当快。此外,我有关于用户和电影的索引,以及它们各自的I。
这个查询的概要文件看起来如下-
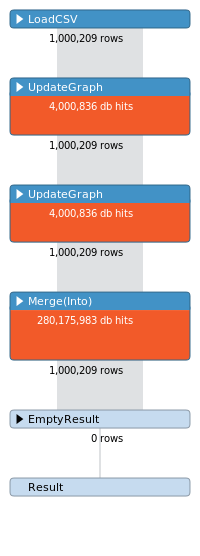
db点击量看起来很不正常,我认为我可以优化这个查询。
(后续问题):我如何在新4j-shell中运行优化的密码查询?这是正确的语法吗-
start [CYPHER_QUERY] ;回答 1
Stack Overflow用户
回答已采纳
发布于 2015-11-11 18:18:45
试试USING PERIODIC COMMIT。http://neo4j.com/docs/stable/query-periodic-commit.html
另外,考虑在最后一行中使用CREATE而不是MERGE来创建关系,因为我假设.csv文件中不会重复评级。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33657056
复制相关文章
相似问题
腾讯云开发者
