
从CYK算法生成解析树的步骤(自然语言处理)
从CYK算法生成解析树的步骤(自然语言处理)
提问于 2015-11-14 06:48:52
我目前正在从事一个涉及NLP的项目。我实现了在Jurafsky和Martin (450页上的算法)中给出的CKY标识符。这样产生的表实际上将非终端存储在表中(而不是通常的布尔值)。但是,我得到的唯一问题是检索解析树。
以下是我的CKY标识符所做工作的说明:
这是我的语法
S -> NP VP
S -> VP
NP -> MODAL PRON | DET NP | NOUN VF | NOUN | DET NOUN | DET FILENAME
MODAL -> 'MD'
PRON -> 'PPSS' | 'PPO'
VP -> VERB NP
VP -> VERB VP
VP -> ADVERB VP
VP -> VF
VERB -> 'VB' | 'VBN'
NOUN -> 'NN' | 'NP'
VF -> VERB FILENAME
FILENAME -> 'NN' | 'NP'
ADVERB -> 'RB'
DET -> 'AT'这就是算法:
for j from i to LENGTH(words) do
table[j-1,j] = A where A -> POS(word[j])
for i from j-2 downto 0
for k from i+1 to j-1
table[i,j] = Union(table[i,j], A such that A->BC)
where B is in table[i,k] and C is in table[k,j]这就是我的解析表填充后的样子:
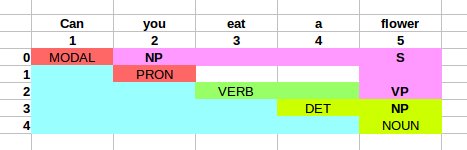
既然S驻留在0,5中,就已经解析了字符串,对于k=1(按照Martin和Jurafsky中给出的算法),我们有了S ->表table2,即S -> NP VP。
我得到的唯一问题是,我已经能够检索所使用的规则,但它们是一种混乱的格式,也就是说,不是基于它们在解析树中的外观。有人能建议一个算法来检索正确的解析树吗?
谢谢你。
回答 1
Stack Overflow用户
回答已采纳
发布于 2015-11-16 21:53:11
您应该递归地访问表中的单元格,并按照对S节点所做的方式展开它们,直到所有的单元格都是终端(因此您没有任何其他需要展开的东西)。在您的例子中,您首先到单元格,这是一个终端,您不需要做任何事情。接下来你去2,这是一个非终点站由2和3。你访问2,它是一个终点站。3是一个非终端,由两个终端组成.你完了。下面是Python中的一个演示:
class Node:
'''Think this as a cell in your table'''
def __init__(self, left, right, type, word):
self.left = left
self.right = right
self.type = type
self.word = word
# Declare terminals
t1 = Node(None,None,'MOD','can')
t2 = Node(None,None,'PRON','you')
t3 = Node(None,None,'VERB', 'eat')
t4 = Node(None,None,'DET', 'a')
t5 = Node(None,None,'NOUN','flower')
# Declare non-terminals
nt1 = Node(t1,t2, 'NP', None)
nt2 = Node(t4,t5, 'NP', None)
nt3 = Node(t3,nt2,'VP', None)
nt4 = Node(nt1,nt3,'S', None)
def unfold(node):
# Check for a terminal
if node.left == None and node.right == None:
return node.word+"_"+node.type
return "["+unfold(node.left)+" "+unfold(node.right)+"]_"+node.type
print unfold(nt4)以及产出:
[[can_MOD you_PRON]_NP [eat_VERB [a_DET flower_NOUN]_NP]_VP]_S页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33705923
复制相关文章
相似问题
腾讯云开发者
