
使用OpenXML替换DOCX文件中的文本-奇怪的内容
我试图使用Microsoft和微软页面上的示例来用Word文档中的实际内容替换占位符。
它曾经像描述的这里那样工作,但是在编辑了Word中的模板文件之后,添加了头和页脚,它就停止了工作。我想知道为什么和一些调试显示了这一点:
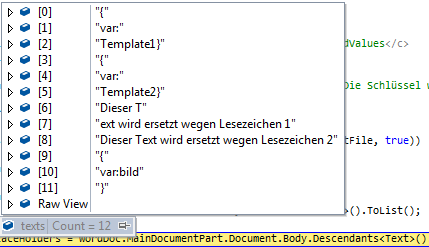
这是这段代码中texts的内容:
using (WordprocessingDocument wordDoc = WordprocessingDocument.Open(DocumentFile, true))
{
var texts = wordDoc.MainDocumentPart.Document.Body.Descendants<Text>().ToList();
}因此,我在这里看到的是,文档的主体是“零碎的”,尽管文字上的内容看起来如下:

谁能告诉我怎么才能绕过这件事吗?
有人问我要达到什么目的。基本上,我想用真实的内容替换用户定义的“占位符”。我想把Word文档当作模板。占位符可以是任何东西。在我上面的例子中,它们看起来像{var:Template1},但这只是我正在玩的东西。基本上可以是任何词。
因此,例如,如果文档包含以下段落:
不要使用名称USER_NAME
例如,用户应该能够用单词admin替换admin占位符,从而保持格式不变。结果应该是
不要使用名称admin
我所看到的问题是,在段落级别上工作,连接内容,然后替换段落的内容,我担心我正在丢失应该保持在
不要使用管理员的名称
回答 2
Stack Overflow用户
发布于 2015-11-30 16:27:40
各种东西都可以分割文本运行。最常见的是校对标记(显然是这样,这里有"squigglies")或rsid (用于比较文档和跟踪谁编辑了什么,何时),以及背景中的“回溯”书签词集。如果您在WordOpenXML“部件”中查看底层document.xml (例如,使用工具),那么这些问题就很明显了。
它通常有助于使元素级别“更高”。在本例中,获取段落后代的列表,并从中获取所有文本后代并连接他们的InnerText。
Stack Overflow用户
发布于 2015-12-01 09:38:05
OpenXML确实正在分割您的文本:
我创建了一个图书馆,它正是这样做的:使用来自JSON的值呈现一个word模板。
为什么要为此使用一个库? Docx是一种压缩格式,包含一些xml。如果您想要构建一个简单的替换{tag}的值系统,它可能已经变得复杂了,因为{tag}在内部被分隔为
<w:t>{</w:t><w:t>tag</w:t><w:t>}</w:t>。如果你想嵌入循环来迭代一个数组,它就变成了一个真正的麻烦。
该库基本上将执行以下操作以保持格式:
如果案文是:
<w:t>Hello</w:t>
<w:t>{name</w:t>
<w:t>} !</w:t>
<w:t>How are you ?</w:t>其结果将是:
<w:t>Hello</w:t>
<w:t>John !</w:t>
<w:t>How are you ?</w:t>您还必须用<w:t xml:space=\"preserve\">替换标记,以确保如果变量中有空格,则不会将其删除。
https://stackoverflow.com/questions/34002797
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号