
从两幅图像中选择OCR的最佳输入
我正在建立一个预处理项目,以增强OCR的结果,将发生在第二阶段,但从两个图像。
例如,我有image1和image2,我们需要检查哪一个更适合在上面执行OCR。
性能和处理时间是如此重要(实时应用).
以下是一些我需要讨论的案例:
Case1

这两个字母都是"F“字母,但第一个字母在OCR中是可读的"F”,接下来发生的OCR中,第二个字母根本无法读取,所以对于第一个例子1,我需要选择第一个"F“作为OCR的输入,忽略第二个图像。
Case2

这两个字母都是"R“字母,在OCR中都是可读的,但是第一个字母比第二个字母要好,所以我需要在这里选择第一个"R”。
Case3:
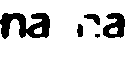
它类似于第一种情况,这里的"n“在OCR中是不可读的,所以我需要选择第一个"na”
Case4
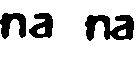
在第一个"na“中,"n”和"a“不合并在一起,其中第二个是”等高线“,因此第一个"na”更适合作为OCR的输入。
我需要建立一个通用的快速算法,以检查这部分图像是否更适合OCR。
--我尝试了以下方法:
1- Method1:检查图像是否模糊,并选择一个更好的。
2- Method2:称为canny方法(或sobel),并选择更好的图像。
3- Method2:检查两幅图像上轮廓的计数,并根据轮廓区域选择一个看起来更好的,并进行计数。
有更好的建议吗?
回答 3
Stack Overflow用户
发布于 2015-12-25 14:55:11
问题是你是怎么得到这些块的?
你怎么确定这些是要比较的。
如果您知道预期字符的大小,那么您可以在比较中使用该大小的块。
Stack Overflow用户
发布于 2015-12-29 06:53:47
我觉得这个问题有点过于宽泛了。对于不同类型的缺陷,我建议采用不同的方法。
对于前2例和可能的第3例,我建议做一个小的形态学close,并将结果与原始结果进行比较。更好的字母在使用close时会改变得更少,因为它没有小孔和小点。比较度量可以简单到与像素绝对差之和一样简单。
Stack Overflow用户
发布于 2015-12-25 06:58:55
你可以试试形态学operations.Have看看这个。ops.html#gsc.tab=0
https://stackoverflow.com/questions/34454175
复制相似问题
腾讯云开发者
