
ipython 'range‘对象没有属性'defaultParallelism’
ipython 'range‘对象没有属性'defaultParallelism’
提问于 2015-12-26 05:18:36
我已经为ipython设置了pyspark,并且在ipython内部,我可以成功地导入pyspark。
我在anaconda,python3.4中使用ipython。这是这个问题的快照。
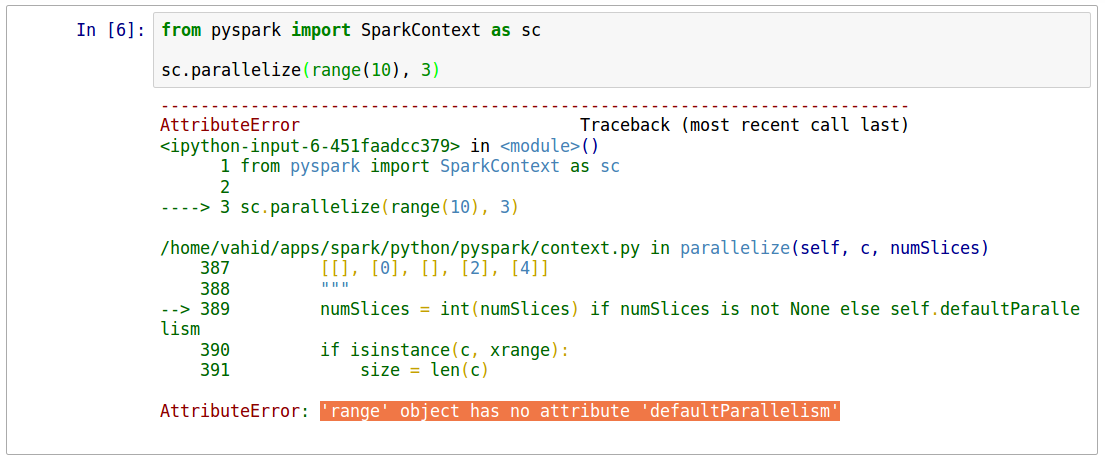
请注意,此命令在pyspark中工作。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.5.2
/_/
Using Python version 2.7.9 (default, Apr 2 2015 15:33:21)
SparkContext available as sc, HiveContext available as sqlContext.
>>> sc.parallelize(range(10), 3)
ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:423
>>>
>>> irdd = sc.parallelize(range(10), 3)
>>> irdd.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> irdd.glom().collect()
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
>>> 我已将其配置如下
export SPARK_HOME=$HOME/apps/spark
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.8.2.1-src.zip:$PYTHONPATHStack Overflow用户
发布于 2017-07-13 15:20:16
为了补充Josh的回答:我遇到了同样的问题,实际上,导入SparkContext作为sc,或者仅仅创建sc = SparkContext并不等于说sc = SparkContext()。
然而,我被告知我有多个SparkContexts运行,它讨厌我。
对我来说,解决办法是使用:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)当我跑的时候:
sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10],4).map(lambda x: x**2).sum()我得到了385的预期答案。因此,关键是getOrCreate方法,因为它允许您找到现有的上下文并使用它。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/34468715
复制相关文章
相似问题
腾讯云开发者
