
如何优化在runtime.osyield和runtime.usleep上花费最多时间的golang程序
如何优化在runtime.osyield和runtime.usleep上花费最多时间的golang程序
提问于 2016-02-02 13:41:31
我一直在优化分析社交图数据的代码(在https://blog.golang.org/profiling-go-programs的大量帮助下),我成功地重新编写了许多缓慢的代码。
所有数据首先从db加载到内存中,来自其中的数据分析出现CPU限制(最大内存消耗<10 db,CPU1 @ 100%)。
但现在我的节目大部分时间似乎都在runtime.osyield和runtime.usleep上。有什么办法可以防止这种情况发生?
我已经设置了GOMAXPROCS=1,代码没有生成任何goroutines (除了golang库可能调用的内容)。
这是我从pprof输出的top10
(pprof) top10
62550ms of 72360ms total (86.44%)
Dropped 208 nodes (cum <= 361.80ms)
Showing top 10 nodes out of 77 (cum >= 1040ms)
flat flat% sum% cum cum%
20760ms 28.69% 28.69% 20850ms 28.81% runtime.osyield
14070ms 19.44% 48.13% 14080ms 19.46% runtime.usleep
11740ms 16.22% 64.36% 23100ms 31.92% _/C_/code/sc_proto/cloudgraph.(*Graph).LeafProb
6170ms 8.53% 72.89% 6170ms 8.53% runtime.memmove
4740ms 6.55% 79.44% 10660ms 14.73% runtime.typedslicecopy
2040ms 2.82% 82.26% 2040ms 2.82% _/C_/code/sc_proto.mAvg
890ms 1.23% 83.49% 1590ms 2.20% runtime.scanobject
770ms 1.06% 84.55% 1420ms 1.96% runtime.mallocgc
760ms 1.05% 85.60% 760ms 1.05% runtime.heapBitsForObject
610ms 0.84% 86.44% 1040ms 1.44% _/C_/code/sc_proto/cloudgraph.(*Node).DeepestChildren
(pprof)_ /C_/ code /sc_proto/*函数是我的代码。
以及网络的输出:
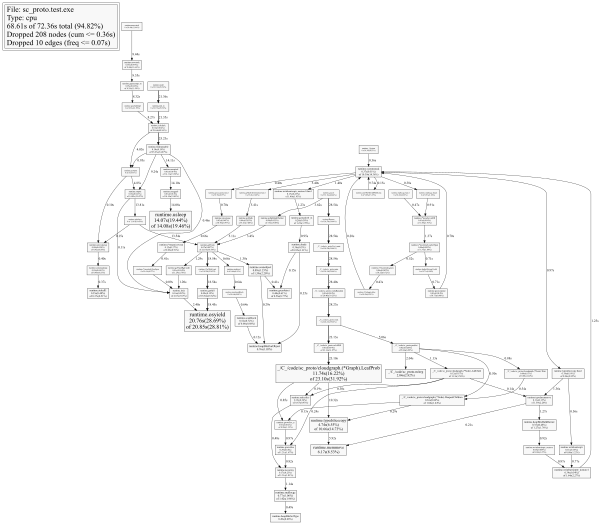
(更好的,SVG版本的图形这里:https://goo.gl/Tyc6X4)
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-02-02 17:57:48
我自己找到了答案,所以我在这里为其他有类似问题的人发这篇文章。特别感谢@JimB让我走上正确的道路。
从图中可以看出,导致os产和usleep的路径是垃圾收集例程。这个程序使用了一个链接列表,它生成了大量的指针,这为gc创建了大量的工作,在清理我的混乱时,gc偶尔会阻止我的代码的执行。
最终,这个问题的解决方案来自于https://software.intel.com/en-us/blogs/2014/05/10/debugging-performance-issues-in-go-programs (这是一个非常棒的资源)。我遵循了关于内存分析器的说明;用切片替换指针集合的建议清除了我的垃圾收集问题,我的代码现在更快了!
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/35155119
复制相关文章
相似问题
腾讯云开发者
