
激活导数在反向传播中的应用
激活导数在反向传播中的应用
提问于 2016-02-04 04:40:24
我有点搞不懂为什么反向传播中的激活导数是这样的。
首先,当我从反向传播算法中删除激活导数并将其替换为常数时,网络仍在训练,尽管速度稍慢。所以我假设它对算法来说并不重要,但是它确实提供了一个性能优势。
但是,如果激活导数是(简单地说),只是激活函数相对于当前输入的变化率,那么为什么这提供了性能改进?
当然,在激活函数变化最快的值中,我们需要一个较小的值,所以权重更新更小?这将防止大的产量变化发生在陡坡附近的活化函数的重量变化。然而,这与算法的实际工作原理完全相反。
有人能向我解释一下为什么它是这样设置的,以及为什么它提供了这样的性能改进吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-02-04 05:52:03
我不完全确定这是否是你想要的,但这个答案可能会给你提供一些关于你想要理解的东西的洞察力。
因此,想象一下错误曲线:
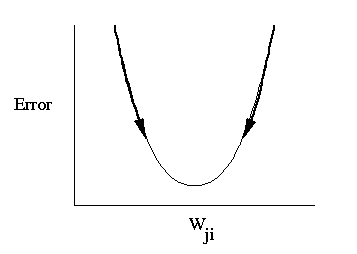
我们试图用梯度下降来最小化成本函数,对吗?假设我们在曲线的最外面,误差很大。通过用该曲线计算坡度下降,该函数将实现坡度陡峭,因此误差较大,因此将采取较大的步长。当它沿着曲线穿过时,斜坡慢慢地接近0,因此每次都会采取较小的步骤。
用激活导数显示梯度下降:
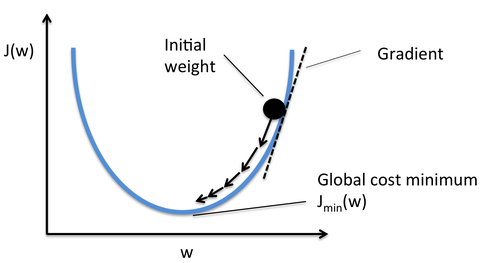
看看它是如何从迈出一大步开始的,每次都采取更小的步骤吗?这是通过使用激活导数来实现的。它从一个大的步骤开始,因为有一个陡峭的曲线。当斜坡变小时,台阶也变小了。
如果您使用一个常量值,您将不得不选择一个非常小的步骤,以避免超过最小值,因此必须使用更多的迭代来实现类似的结果。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/35192628
复制相关文章
相似问题
腾讯云开发者
