
确定两个python系列或dataframes中的额外值。
确定两个python系列或dataframes中的额外值。
提问于 2016-02-11 01:23:52
给定两个数据格式,我将一些唯一的值提取到一个groupby中,然后我想比较两个唯一的值,并找到不同的值。
unit1 = ["U1", "U2", "U1", "U2", "U1", "U2"]
unit2 = ["U1", "U2", "U1", "U2", "U1", "U2, "U3"]
count1 = [2,4,6,8,10,12]
df = pd.DataFrame({'Unit': unit1,
'Count': count1})
df2 = pd.DataFrame({'Unit': unit2,
'Count': count1})
units_in_1 = df.groupby(['Unit'])
unit1_list = units_in_1['Unit'].unique()
units_in_2 = df2.groupby(['Unit'])
unit2_list = units_in_2['Unit'].unique()我最终想要的是U3,这样我就可以返回并在df2中找到所有的实例。
unit1_list是一个系列,我似乎什么都做不了。
创建一个列表并按照this answer执行一个交集将失败,因为著名的numpy,not
如果我尝试减法,就会得到str和str不受支持的TypeError操作数。
请帮帮忙。
回答 3
Stack Overflow用户
回答已采纳
发布于 2016-02-11 09:51:05
您可以使用isin()和否定(~)运算符来实现这一点。
>>> stuff_in_df2_but_not_in_df1 = df2[~df2.Unit.isin(df1.Unit)]['Unit'].unique()
['U3']这一行有点神秘的代码告诉Pandas给出df2['Unit']中没有出现在df1['Unit']中的所有项目。
如果您想让它在两个方向工作(也就是说,您想要一个df1中的东西列表,但不是df2中的东西,以及df2中的东西,而不是df1中的东西),那么您可以使用set.symmetric_difference()。
如果df1['Unit']包含U1, U2, U4,df2['Unit']包含U1, U2, U3,下面的代码将为您提供一个包含{'U3', 'U4'}的set()。
>>> set(df1.Unit.unique()).symmetric_difference(set(df2.Unit.unique()))
{'U3', 'U4'}Stack Overflow用户
发布于 2016-02-11 02:02:17
希望我能理解你的问题。
如果您选择不等于df'Unit的df2'Unit的任何值,它是否有效?
df2[df.Unit != df2.Unit ]产出:
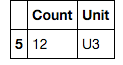
Stack Overflow用户
发布于 2016-02-11 09:24:58
然后您可以创建一个唯一值的set,然后调用difference。
In [161]:
combined = set(df['Unit'].unique().tolist()+df2['Unit'].unique().tolist())
combined
Out[161]:
{'U1', 'U2', 'U3'}
In [162]:
combined.difference(df['Unit'].unique())
Out[162]:
{'U3'}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/35329183
复制相关文章
相似问题
腾讯云开发者
