
增强拓扑的NeuroEvolution (NEAT)和全球创新数
我没能找到为什么我们应该有一个全球创新的数字,每一个新的连接基因在整洁。
从我对整洁的一点了解来看,每个创新数都直接对应于一个node_in,node_out对,那么,为什么不仅仅使用这对ids而不是创新号呢?在这个创新数字中有哪些新的信息?年表?
更新
这是算法优化吗?
回答 4
Stack Overflow用户
发布于 2017-04-01 16:04:05
注:这与其说是一个回答,不如说是一个延伸的评论。
在为javascript开发一个整洁的版本时,您遇到了一个我刚刚遇到的问题。2002年发表的原始论文很不清楚。
原纸包含以下内容:
每当一个新基因出现时(通过结构突变),全球创新数就会增加,并分配给该基因。因此,创新数据代表了系统中每一个基因的出现时间顺序。。。创新的数量从未改变过。因此,在整个进化过程中,系统中每一个基因的历史起源都是已知的。
但论文对以下情况非常不清楚,比如我们有两个相同的网络:‘相同的’(相同的结构)网络:
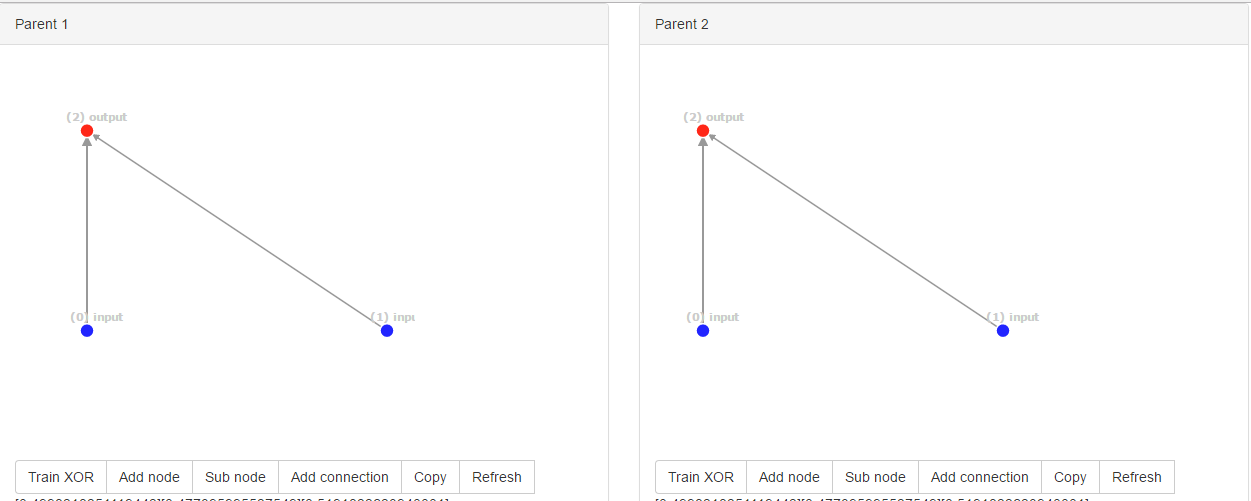
以上网络是初始网络,网络具有相同的创新ID,即[0, 1]。所以现在网络随机突变一个额外的连接。
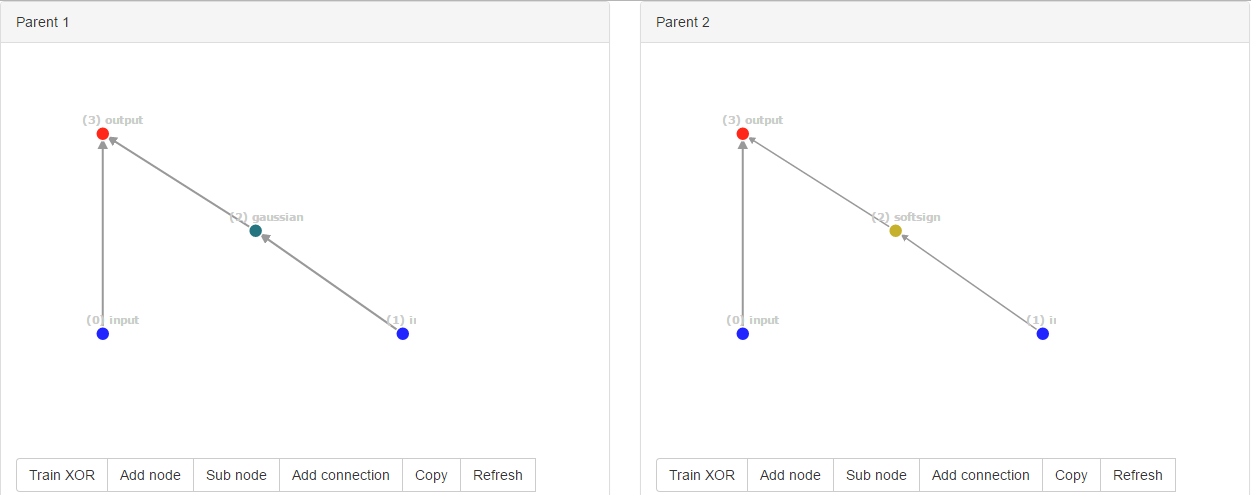
轰隆隆!偶然地,它们变异成了同样的新结构。但是,连接ID是完全不同的,即[0, 2, 3]用于parent1,[0, 4, 5]用于parent2,因为ID是全局计算的。
但是,NEAT算法无法确定这些结构是否相同。当父母一方得分高于另一方时,这不是问题。但是当的父母有同样的健康状况时,我们就有问题了。--
因为这份文件说:
在组成后代的过程中,基因是随机从双亲中随机选择的,而所有多余的或不相交的基因都来自更合适的亲本,或者如果它们同样合适的话,则来自父母双方。
因此,如果父母同样健康,后代就会有[0, 2, 3, 4, 5]的关系。这意味着有些节点有双重连接。移除全球创新计数器,只需通过查看node_in和node_out来分配id,就可以避免这个问题。
所以,当你有同样合适的父母时,是的,你优化了算法。但几乎从来都不是这样的。
非常有趣:在论文的更新版本中,他们实际上删除了这一行。旧版本的这里。
顺便说一句,您可以通过使用node_in和node_out来解决这个问题,而不是分配创新ID,而是使用配对函数。当适应度相等时,这会产生相当有趣的神经网络:

Stack Overflow用户
发布于 2016-08-15 23:29:27
我无法给出一个详细的答案,但创新数使整洁模型中的某些功能成为最佳(比如计算一个基因的种类),以及允许可变长度基因组之间的交叉。交叉是没有必要的整洁,但它可以做,因为创新的数目。
我从这里得到了所有的答案:
http://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf
这是一个很好的阅读
Stack Overflow用户
发布于 2019-03-18 23:33:15
在交叉过程中,我们必须考虑两个基因组,在它们的个人神经网络中,两个相同的节点之间有着相同的连接。我们如何在不重复基因组的连接基因的情况下,在每一步交叉中检测到这种碰撞?简单:如果在交叉过程中被检查的两个连接共享一个创新号,那么它们将连接相同的两个节点,因为它们是从相同的共同祖先接收到的连接。
简单的例子:如果我是一个与创新号“i”有特定联系基因的基因组,那么我的孩子们,如果把基因'i‘从我身上夺走,可能会在100代的时间里相互交叉。我们必须检测我的基因'i‘的这两个进化版本(等位基因)何时发生碰撞,以防止两者兼而有之。接受两个相同的基因将导致表型可能循环和崩溃,杀死基因型。
https://stackoverflow.com/questions/36223165
复制相似问题
腾讯云开发者
