
利用图形数据库进行主数据管理
我正在建立一个主数据库来存储关于我们客户的所有相关信息。我正在使用Neo4j。
下面是我们模型的样本。我们有Person,可以在我们的三个移动应用程序中注册。(App.01,App. 02,App. 03 -我们使用CPF密钥,它就像一个SSN)。在这些应用程序中,用户可以通过电子邮件注册。因此,它是用Email实体表示的。这些用户可以具有由Address实体表示的多个地址。
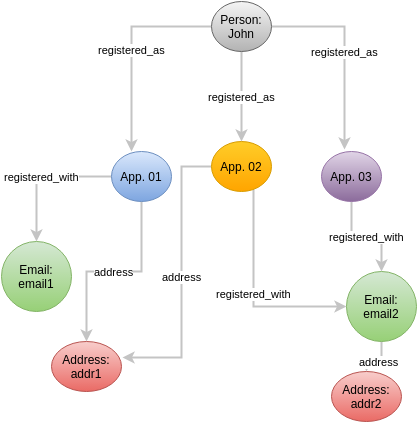
问题是:当我正在构建一个主数据时,海事组织,如果有人查询mdm数据库,询问关于一个人的所有“最佳”信息,我会返回例如:名称: John : email2 (因为它有两个应用程序使用它):addr1 (因为它有两个应用程序使用它)
因此,我将建立一些启发式来定义什么是“最好的”电子邮件和地址。
为此,我有一些选择:
- 我可以创建一个从
John到email2和addr1的边缘。因此,MDM的用户很容易从John那里获得“最佳”地址/电子邮件。 - 我可以构建一个rest端点,并在查询时间内创建这个启发式。
是否有人有使用图形数据库或设计MDM数据库的经验?这是个好方法吗?
这个问题是对问题:Using Neo4j to build a Master Data Management的补充
回答 2
Stack Overflow用户
发布于 2019-11-02 05:49:42
图形数据模型很好地存储了您的主数据,但是,您的主数据很可能以维度的形式与操作数据和参考数据共存。如果您决定使用DMD的图形模型,请确保为核心维度MDM提供了定义良好的语义模型,通常如下:
- 产品
- 客户
- 员工
- 资产
- 位置
这些核心维度成为节点的属性。
另外,确定您将要采用的DMD架构风格,一些流行的DMD架构样式是:
- 注册表-图非常适合这种风格,因为您的主数据保留在SOS(记录系统)中,并且引用可以很好地在图中表示。
- 主数据集线器-将记录系统从表格转到图形所需的额外转换( ar4e )。
- 师父-师父。-如果您没有太多依赖MDM的遗留应用程序,则这种样式非常适合图表中的MDM。
Stack Overflow用户
发布于 2016-04-13 19:48:16
方法1将添加大量本质上多余的信息(大约2N额外的关系,其中N是人数),还需要更复杂的编码来处理对个人应用程序的更改。而且,与往常一样,当信息被冗余地存储时,您必须特别小心,以免出现不一致之处。但是,当查询“最佳”联系人信息时,应该会更快。
方法2使DB保持相同的大小,但需要更复杂和更慢的查询才能获得“最佳”联系人信息。然而,改变一个人的应用程序和联系方式是很简单的。
要决定使用哪种方法,您应该考虑DB大小是否是一个问题,并查看您的用例以及它们的执行频率。
下面是一个简单的启发,如果DB大小不是一个问题。假设G是您需要获取一个人的“最佳”联系人信息的频率,而M是您需要修改一个人的应用程序或联系人信息的频率。如果G/M的值超过某个阈值K,您将选择方法1,考虑到上述考虑,您必须对其作出决定。
https://stackoverflow.com/questions/36604791
复制相似问题
腾讯云开发者
