
快速采矿器不保存爬虫Web结果
快速采矿器不保存爬虫Web结果
提问于 2016-04-18 05:32:52
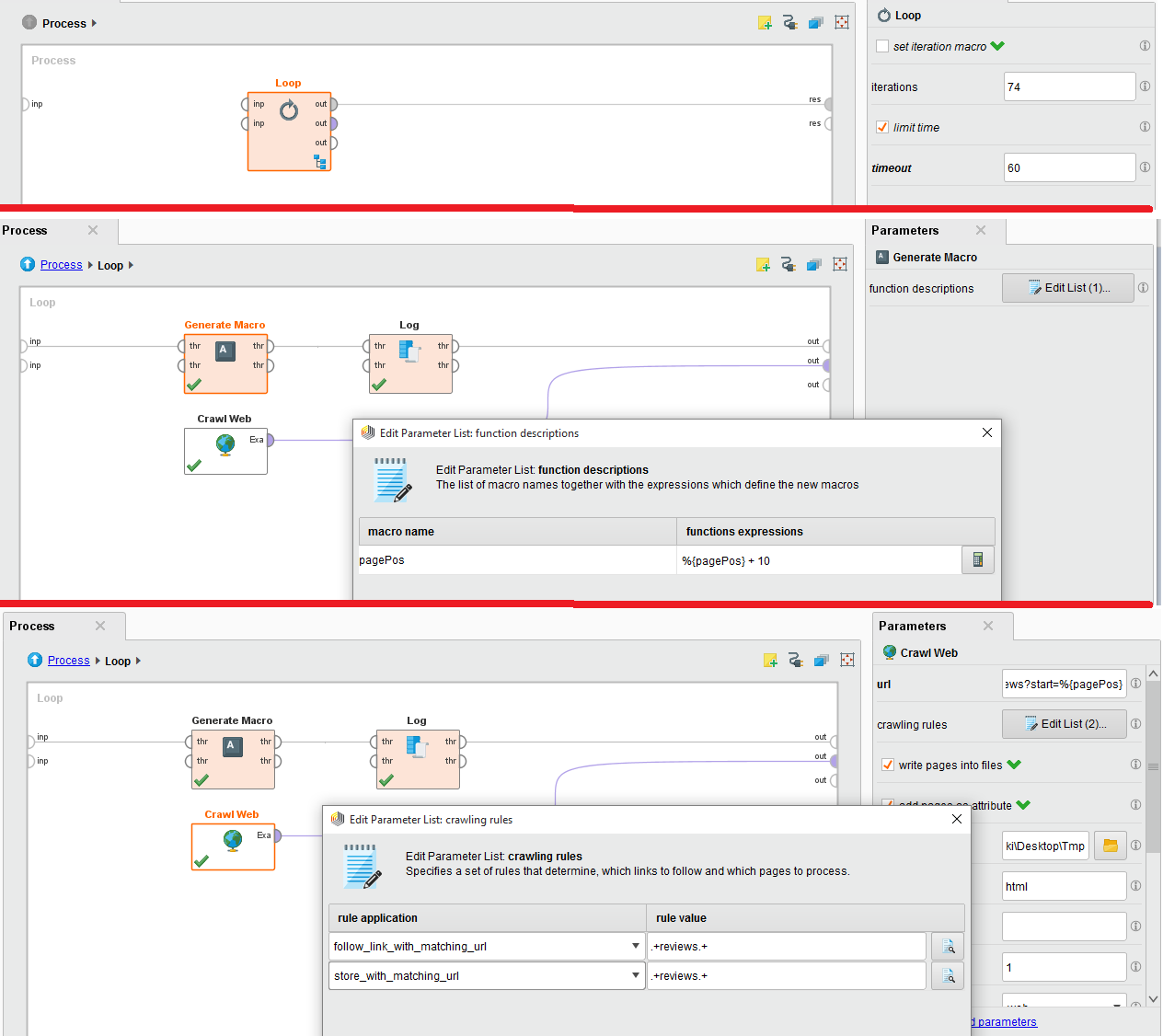
我试图从IMDB网站上抓取一个特定电影评论的评论。为此,我使用爬行网站,我已经嵌入循环,因为有74页。
附件是配置的图像。请帮帮忙。我被困在这里面了。
爬网网址是:http://www.imdb.com/title/tt0454876/reviews?start=%{pagePos}
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-04-18 14:59:09
当我尝试时,我得到了403 forbidden错误,因为IMDB服务认为我是一个机器人。将Loop与Crawl Web一起使用是错误的做法,因为Loop操作符没有实现任何等待。
可以将此过程简化为只使用Crawl Web操作符。主要参数如下:
- 将此设置为http://www.imdb.com/title/tt0454876
- max pages -将此设置为79或任何您需要的数字
- 最大页面大小-将此设置为1000
- 爬行规则-将这些规则设置为您指定的规则
- output dir -选择一个文件夹将事物存储在
这是因为爬行操作符将计算出与规则匹配的所有可能的URL,并存储同样匹配的URL。访问将延迟1000 ms (延迟参数),以避免在服务器上触发机器人排斥。
希望这能让你开始。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36686110
复制相关文章
相似问题
腾讯云开发者
