
如何使用Arelle的Python从XBRL文件中提取财务报表?
如何使用Arelle的Python从XBRL文件中提取财务报表?
提问于 2016-04-22 14:59:33
不知怎么的,在Arelle的python API文档失效的情况下,我设法使该API正常工作,并成功地加载了一个XBRL文件。
总之,我的问题是:
如何仅从XBRL文件中提取语句?
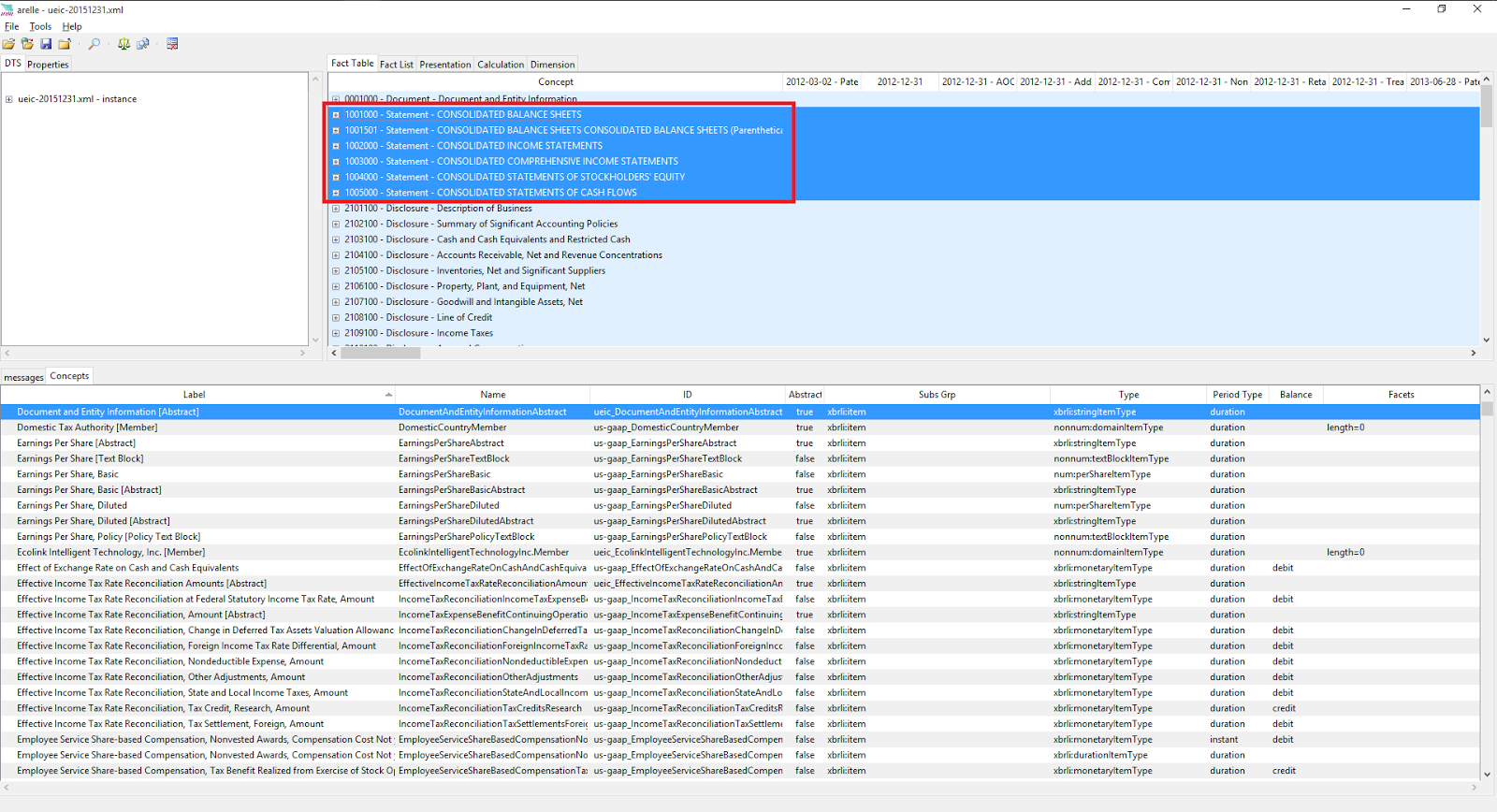
下面是Arelle Windows应用程序的截图。
本例中使用的URL:https://www.sec.gov/Archives/edgar/data/101984/000010198416000062/ueic-20151231.xml
我试着用API做实验,下面是我的代码
from arelle import Cntlr
xbrl = Cntlr.Cntlr().modelManager.load('https://www.sec.gov/Archives/edgar/data/101984/000010198416000062/ueic-20151231.xml')
for fact in xbrl.facts:
print(fact)但是在执行了这个片段之后,我被这些代码轰炸了:
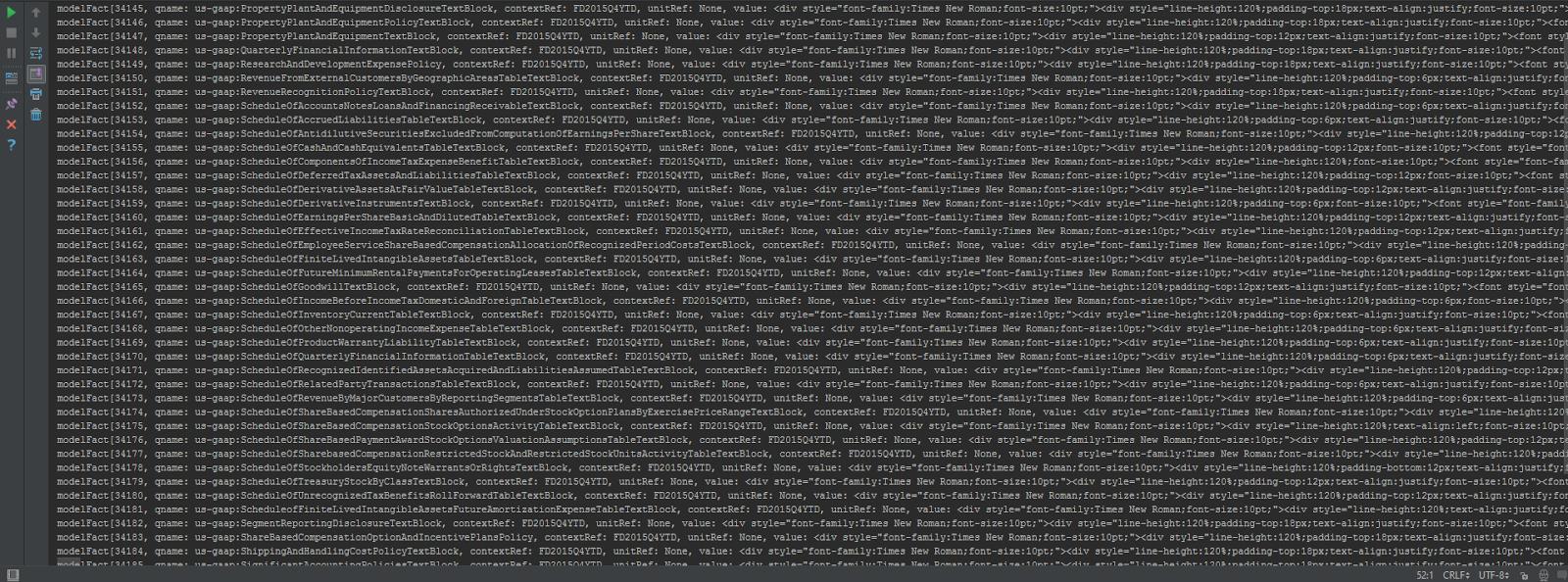
我试着在每个modelFact中获得可用的密钥,这是contextRef、id、decimals和unitRef之间的混合,这对我想要提取的内容没有帮助。由于没有任何文件可以帮助进一步解决这个问题,我对此感到困惑。有人能教我如何实现只提取语句吗?
回答 1
Stack Overflow用户
发布于 2016-05-26 20:55:16
我正在做一些类似的事情,到目前为止已经取得了一些进展,我可以分享:
通过arelle的python代码文件,您可以检测可以访问不同类(如ModelFact、ModelContext、ModelUnit等)的属性。
例如,要提取单个数据,可以将它们放在熊猫数据中,如下所示:
factData=pd.DataFrame(data=[(fact.concept.qname,
fact.value,
fact.isNumeric,
fact.contextID,
fact.context.isStartEndPeriod,
fact.context.isInstantPeriod,
fact.context.isForeverPeriod,
fact.context.startDatetime,
fact.context.endDatetime,
fact.unitID) for fact in xbrl.facts])现在更容易处理所有的数据,过滤您想要使用的数据等等。如果您想要复制语句表,您还需要将每个事实和数据的链接合并起来,而不是顺序和排序,但我也没有做到这一点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36797207
复制相关文章
相似问题
腾讯云开发者
