
无法找到用于抓取的html标记。
无法找到用于抓取的html标记。
提问于 2016-04-28 02:44:32
我在HTML方面不是很好,所以我对此感到有点困惑。
我正在尝试使用python抓取instagram日期时间帖子,并意识到日期时间信息并非没有文章的html文档。但是,我可以使用inspect元素来查询它。见下面的屏幕截图。
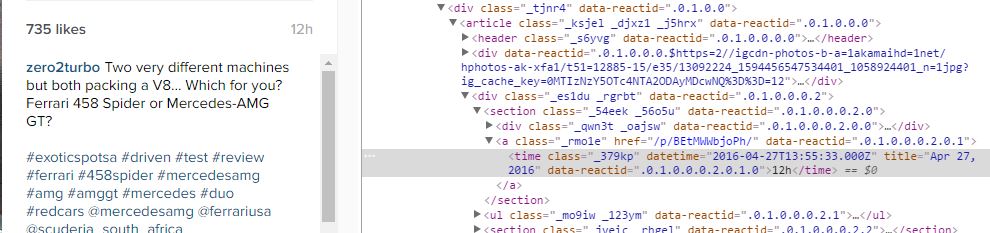
这个日期时间信息准确定位在哪里,我如何获得它?
我从这个随机发布的帖子"https://www.instagram.com/p/BEtMWWbjoPh/“中得到了一个例子。元素位于页面中显示的"12h“处。
更新--我使用urllib获取url,在python中使用bs4来抓取。输出没有返回日期时间的任何内容。代码在下面。我还打印出了整个html,并且惊讶于它中没有包含日期时间。
html = urllib.urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
tags = soup.select('time')
for tag in tags:
dateT = tag.get('datetime').getText()
print dateT回答 1
Stack Overflow用户
发布于 2016-04-28 02:53:16
在开发人员控制台中,键入以下内容:
document.getElementsByTagName('time')[0].getAttribute('datetime');这将返回您正在寻找的数据。上面的代码只是简单地查看HTML中的标签名time (其中只有一个),然后从其中获取datetime属性。
至于python,如果还没有,请查看BeautifulSoup。这个库将允许您在python中执行类似的操作:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
soup.time['datetime']其中html_doc是原始的HTML。若要获取原始HTML,请使用requests库。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/36904343
复制相关文章
相似问题
腾讯云开发者
