
熊猫专栏创作
考虑到创建新列的下列尝试之一似乎失败了,我很难理解列命名约定背后的概念:
from numpy.random import randn
import pandas as pd
df = pd.DataFrame({'a':range(0,10,2), 'c':range(0,1000,200)},
columns=list('ac'))
df['b'] = 10*df.a
df给出以下结果:
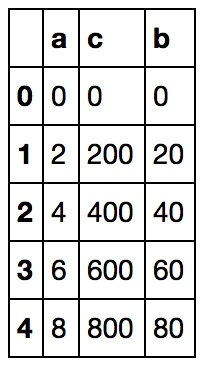
但是,如果我试图用下面的行替换来创建列b,则不会出现错误消息,但是dataframe只保留列a和c。
df.b = 10*df.a ### rather than the previous df['b'] = 10*df.a ###熊猫做了什么?为什么我的命令不正确?
回答 3
Stack Overflow用户
发布于 2016-04-28 20:13:35
您所做的是向df添加属性b:
In [70]:
df.b = 10*df.a
df.b
Out[70]:
0 0
1 20
2 40
3 60
4 80
Name: a, dtype: int32但我们看到没有增加新的一栏:
In [73]:
df.columns
Out[73]:
Index(['a', 'c'], dtype='object')这意味着,如果尝试使用KeyError,就会得到一个df['b'],为了避免这种模糊性,在赋值时应该始终使用方括号。
例如,如果您有一个名为index、sum或max的列,那么执行df.index将返回索引,而不是索引列,同样,df.sum和df.max会破坏这些df方法。
我强烈建议您始终使用方括号,这样可以避免任何歧义,而且最新的ipython能够使用方括号解析列名。将dataframe看作是系列的一个片段也很有用,在这个系列中使用方括号来分配和返回列是有意义的
Stack Overflow用户
发布于 2016-04-28 20:24:25
总是使用方括号来分配列
点表示法是访问dataframe中的列的一种方便。如果它们与现有属性相冲突(例如,如果您有一个名为‘max’的列,则需要使用方括号来访问该列,例如df['max']。当列名包含空格(例如df['max value'] )时,还需要使用方括号。
DataFrame只是一个具有通常属性和方法的对象。如果使用点表示法进行赋值,则正在为dataframe对象创建属性或方法。因此,df.val = 2将为df分配一个值为2的属性val。这与df['val'] = 2非常不同,后者在dataframe中创建了一个新列,并为该列中的每个元素分配了两个的值。
为了安全起见,使用方括号符号将始终提供正确的结果。
顺便说一句,您的columns=list('ac'))什么也不做,因为您只是在创建一个名为columns的变量,它从未被使用过。您可能是指df.columns = list('ac'),但是您已经在创建dataframe时分配了这些数据,所以我不确定这一行代码的目的是什么。请记住,字典是无序的,因此pd.DataFrame({'a': [...], 'b': [...]})可能会返回列为'b‘、'a’的数据。如果是这样的话,那么分配列名可能会混淆列标题。
Stack Overflow用户
发布于 2016-04-28 20:28:27
这个问题与python中如何处理属性有关。python中没有为类设置新属性的限制,例如,您可以执行以下操作
df.myspecialstuff = ["dog", "cat", 5]所以当你做任务的时候
df.b = 10*df.a是否要添加属性或新列,并设置属性,这是不明确的。要真正了解这其中发生了什么,最简单的方法是使用pdb并逐步完成代码。
import pdb
x = df.a
pdb.run("df.a1 = x")这将进入__setattr__(),而pdb.run("df['a2'] = x")将进入__setitem__()
https://stackoverflow.com/questions/36924407
复制相似问题
腾讯云开发者
