
LRM与GLM输出的不同系数
LRM与GLM输出的不同系数
提问于 2016-05-16 21:05:44
首先,请允许我指出,我无法在数据集之外的任何内容上重现此错误。然而,这是一个普遍的想法。我有一个数据框架,我试图建立一个简单的logistic回归来理解数量对IsWon的边际效应。这两种模型的性能都很差,毕竟是一个预测器,但它们产生了两个不同的系数
首先是glm输出:
> summary(mod4)
Call:
glm(formula = as.factor(IsWon) ~ Amount, family = "binomial",
data = final_data_obj_samp)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.2578 -1.2361 1.0993 1.1066 3.7307
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.18708622416 0.03142171761 5.9540 0.000000002616 ***
Amount -0.00000315465 0.00000035466 -8.8947 < 0.00000000000000022 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 6928.69 on 4999 degrees of freedom
Residual deviance: 6790.87 on 4998 degrees of freedom
AIC: 6794.87
Number of Fisher Scoring iterations: 6注意量的负系数。
而现在rms的lrm功能
Logistic Regression Model
lrm(formula = as.factor(IsWon) ~ Amount, data = final_data_obj_samp,
x = TRUE, y = TRUE)
Model Likelihood Discrimination Rank Discrim.
Ratio Test Indexes Indexes
Obs 5000 LR chi2 137.82 R2 0.036 C 0.633
0 2441 d.f. 1 g 0.300 Dxy 0.266
1 2559 Pr(> chi2) <0.0001 gr 1.350 gamma 0.288
max |deriv| 0.0007 gp 0.054 tau-a 0.133
Brier 0.242
Coef S.E. Wald Z Pr(>|Z|)
Intercept 0.1871 0.0314 5.95 <0.0001
Amount 0.0000 0.0000 -8.89 <0.0001 这两种模型都做得很差,但其中一个估计了一个正系数,另一个估计了一个负系数。当然,这些值可以忽略不计,但是有人能帮我理解这一点吗?
至于它的价值,以下是lrm对象的情节。
> plot(Predict(mod2, fun=plogis))
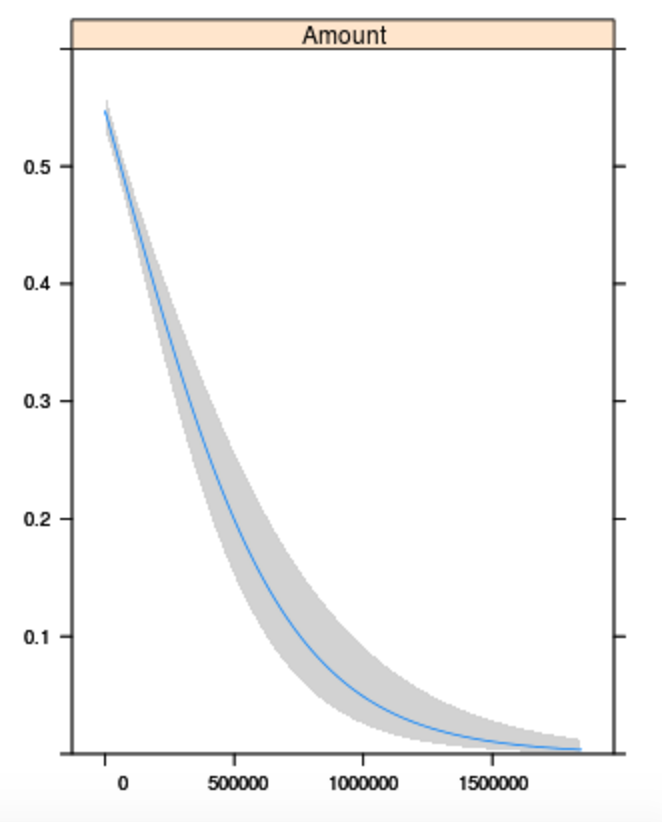
情节显示,预测的获胜概率与数量呈非常负相关的关系。
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-05-16 21:20:00
您不应该依赖于summary打印的结果来检查系数。汇总表由print控制,因此始终存在舍入问题。你试过mod4$coef ( glm模型mod4的get系数)和mod2$coef ( lrm模型mod2的get系数)吗?阅读?glm和?lrm的“值”部分是个好主意。
Stack Overflow用户
发布于 2016-05-16 21:13:40
看来lrm是在估计系数到最近的±0.0000值。由于系数值远低于这个值,它只是将其舍入到0.0000。因此,这似乎是积极的,但实际上可能不是。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37263248
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号