
如何在ggplot2图中包含簇中的成员号,并为不同的簇选择不同的颜色方案
如何在ggplot2图中包含簇中的成员号,并为不同的簇选择不同的颜色方案
提问于 2016-06-02 22:31:25
我有这样的数据,基本上是它的事务量,它属于哪个集群,其中最小的集群。
TranAmount whichCLuster smallestCluster
1: 344.96 3 4
2: 244.15 3 4
3: 342.23 3 4
4: 44.77 3 4
5: 8052.48 1 4
6: 184.78 3 4
7: 11.19 3 4
8: 1355.71 3 4
9: 1162.07 3 4
10: 461.95 3 4
11: 83.97 3 4
12: 344.37 3 4
13: 648.03 3 4
14: 2122.39 2 4
15: 295.29 3 4
16: 474.32 3 4
17: 2111.72 2 4
18: 950.63 3 4
19: 1246.47 3 4
20: 138.79 3 4
21: 917.79 3 4
22: 112.00 3 4
23: 378.65 3 4
24: 47.57 3 4
25: 5610.00 2 4
26: 1453.69 3 4
27: 1058.01 3 4
28: 955.77 3 4
29: 277.07 3 4
30: 861.53 3 4
31: 296.76 3 4
32: 465.04 3 4
33: 159.65 3 4
34: 3625.25 2 4
35: 197.08 3 4
36: 162.38 3 4
37: 1460.08 3 4
38: 438.74 3 4
39: 564.15 3 4
40: 389.44 3 4
41: 1924.62 2 4
42: 190.39 3 4
43: 565.41 3 4
44: 78.39 3 4
45: 2926.92 2 4
46: 375.16 3 4
47: 679.84 3 4
48: 70.55 3 4
49: 1048.84 3 4
50: 778.08 3 4
51: 709.48 3 4
52: 44.79 3 4
53: 7299.93 1 4
54: 718.44 3 4
55: 386.39 3 4
56: 2140.68 2 4
57: 1554.99 3 4
58: 310.18 3 4
59: 117.78 3 4
60: 1272.57 3 4
61: 645.75 3 4
62: 197.56 3 4
63: 1086.34 3 4
64: 145.58 3 4
65: 403.19 3 4
66: 2185.76 2 4
67: 232.36 3 4
68: 730.05 3 4
69: 2462.77 2 4
70: 377.97 3 4
71: 240.02 3 4
72: 632.79 3 4
73: 11.19 3 4
74: 167.98 3 4
75: 43.31 3 4
76: 1255.92 3 4
77: 2704.71 2 4
78: 118.68 3 4
79: 294.55 3 4
80: 1686.28 3 4
81: 92.94 3 4
82: 83.92 3 4
83: 1756.05 3 4
84: 255.83 3 4
85: 264.97 3 4
86: 586.85 3 4
87: 1010.53 3 4
88: 155.03 3 4
89: 424.47 3 4
90: 360.04 3 4
91: 674.85 3 4
92: 16.24 3 4
93: 646.67 3 4
94: 520.71 3 4
95: 1593.08 3 4
96: 108.64 3 4
97: 190.90 3 4
98: 511.81 3 4
99: 576.50 3 4
100: 1752.84 3 4我想把它画成x轴是whichCLuster,y轴是TranAmount,现在我的代码是
dd <- ggplot(data=data,aes(x=whichCLuster,y=TranAmount,color=whichCLuster))
dd+ geom_point()这给了我一个接近我所需要的情节

但是我也不想在图中包含每个集群的条目,.I可以通过这个获得信息,但不确定在哪里绘制,以及如何,请协助
> data[,.N,whichCLuster]
whichCLuster N
1: 3 2024
2: 1 140
3: 2 672
4: 4 3
5: 5 21回答 3
Stack Overflow用户
回答已采纳
发布于 2016-06-02 23:00:44
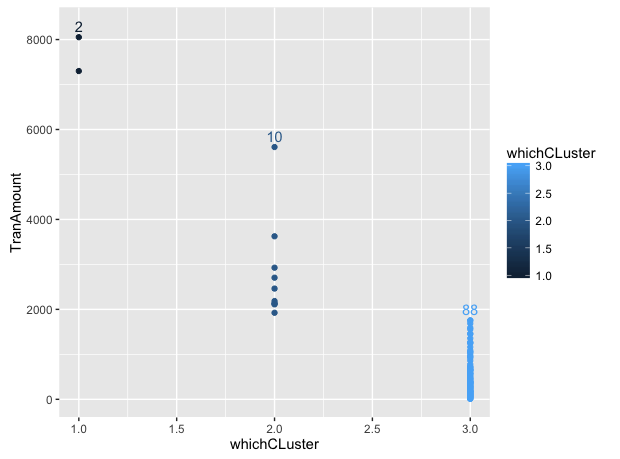
这是我对这个问题的尝试。我的想法是添加一个文本,显示每个组中观察的数量。首先,由于WhichCLuster是离散的,我发现在离散尺度上着色可能更合理。其次,我创建了另一个名为data.frame的df2,它包含每个集群中观察到的总数和TranAmount的中值的信息。中位数可以帮助我们定位文本的位置。
# Use the median to get the location of the text
df2 <- df[, .(Total=.N, Median=median(TranAmount)), whichCLuster]
ggplot(df, aes(x=as.factor(whichCLuster), y=TranAmount, color=as.factor(whichCLuster))) +
geom_point() +
geom_text(data=df2, aes(x=whichCLuster, y=Median, label=Total), hjust=-0.5,
show.legend=FALSE) +
scale_color_discrete("WhichCLuster") +
labs(x="WhichCLuster")
Stack Overflow用户
发布于 2016-06-02 23:02:12
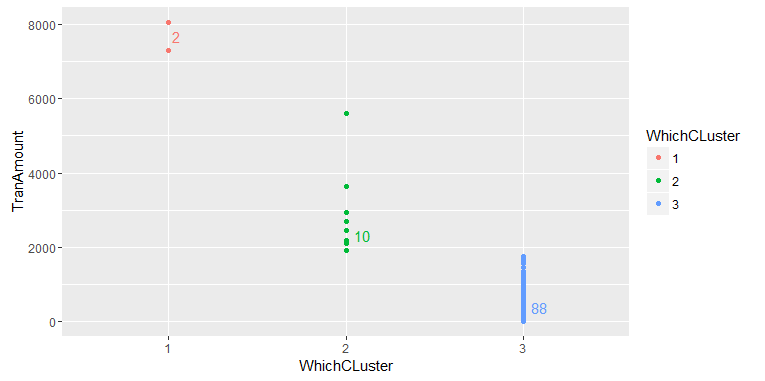
有很多方法可以做到这一点,但是继续您正在使用的方法,您可以向geom_text传递一个新的聚合数据集:
library(data.table)
library(ggplot2)
ggplot(data=dt, aes(x = whichCLuster, y = TranAmount, color = whichCLuster)) +
geom_point() +
geom_text(data = dt[, .(.N, height = max(TranAmount)), by = whichCLuster],
aes(label = N, x = whichCLuster, y = height), nudge_y = 250)
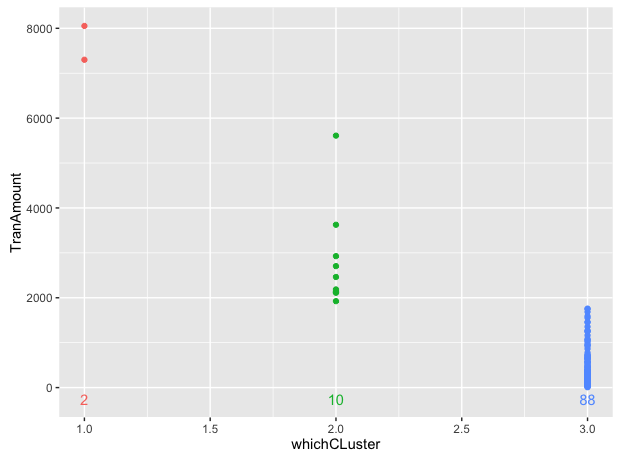
或者把标签放在下面:
ggplot(data=dt, aes(x = whichCLuster, y = TranAmount, color = factor(whichCLuster))) +
geom_point(show.legend = F) +
geom_text(data = dt[, .N, by = whichCLuster],
aes(label = N, x = whichCLuster, y = -250), show.legend = F)
数据
dt <- structure(list(TranAmount = c(344.96, 244.15, 342.23, 44.77,
8052.48, 184.78, 11.19, 1355.71, 1162.07, 461.95, 83.97, 344.37,
648.03, 2122.39, 295.29, 474.32, 2111.72, 950.63, 1246.47, 138.79,
917.79, 112, 378.65, 47.57, 5610, 1453.69, 1058.01, 955.77, 277.07,
861.53, 296.76, 465.04, 159.65, 3625.25, 197.08, 162.38, 1460.08,
438.74, 564.15, 389.44, 1924.62, 190.39, 565.41, 78.39, 2926.92,
375.16, 679.84, 70.55, 1048.84, 778.08, 709.48, 44.79, 7299.93,
718.44, 386.39, 2140.68, 1554.99, 310.18, 117.78, 1272.57, 645.75,
197.56, 1086.34, 145.58, 403.19, 2185.76, 232.36, 730.05, 2462.77,
377.97, 240.02, 632.79, 11.19, 167.98, 43.31, 1255.92, 2704.71,
118.68, 294.55, 1686.28, 92.94, 83.92, 1756.05, 255.83, 264.97,
586.85, 1010.53, 155.03, 424.47, 360.04, 674.85, 16.24, 646.67,
520.71, 1593.08, 108.64, 190.9, 511.81, 576.5, 1752.84), whichCLuster = c(3L,
3L, 3L, 3L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 3L, 3L, 2L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
2L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 3L, 3L, 3L, 2L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 1L, 3L, 3L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
2L, 3L, 3L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L), smallestCluster = c(4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L)), .Names = c("TranAmount",
"whichCLuster", "smallestCluster"), row.names = c(NA, -100L), class = c("data.table",
"data.frame"), .internal.selfref = <pointer: 0x102804778>)Stack Overflow用户
发布于 2016-06-02 23:29:28
Geom_point(x=factor(WhichCluster),y=TranAmount,col=factor(WhichCluster))+ geom_point(data=df,.N,by=whichCluster,aes(x=factor(whichCluster),y=N,col=factor(WhichCluster)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37603189
复制相关文章
相似问题
腾讯云开发者
