
是否有一种有效地索引逗号分隔列的每个值的方法?
是否有一种有效地索引逗号分隔列的每个值的方法?
提问于 2016-06-07 07:08:09
我正在设计一个schema,其中我有一个带有"LanguagesSpoken“列的"Contact”表,该列可能有多个值,例如'en,fr‘。
我想查询Contact表,以检索讲特定语言的每个联系人:
select * from Contact where LanguagesSpoken like '%en%'
然而,就性能而言,这对我来说不是一个令人满意的解决方案。是否有方法通过索引CSV列的每个单独值来提高性能?
Stack Overflow用户
发布于 2016-06-07 07:24:53
摘要中,如果要将数据存储在逗号分隔列表中,则没有能够提供良好性能的索引。
即使使用like条件,如果列上有索引,则SQL可以准确地猜测字符串统计,只要字符串小于80 characters.if字符串超过80个字符,就需要使用前40个和最后40个字符在该字符串column.Other上创建统计信息,而不是这样,使用like和存储数据的方式没有任何优势。
演示:
create table
#test
(
id int,
langspoken varchar(100)
)
insert into #test
select 1,'en,fr,ger,en_us'
union all
select 2,'en,fr'
go 100
create index nci on #test(langspoken)
select * from #test where langspoken like '%fr%'现在允许查看估计数:
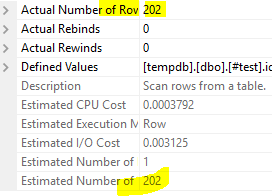
此外,如果您无法以分隔的方式存储数据,那么查询数据的准确方法如下所示,使用这里的字符串函数之一。
create table
#test
(
id int,
langspoken varchar(100)
)
insert into #test
select 1,'en,fr,ger,en_us'
union all
select 2,'en,fr'
select * from #test t
cross apply
dbo.SplitStrings_Numbers(t.langspoken,',')
where item='en'页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37672662
复制相关文章
相似问题
腾讯云开发者
