
R数据框架中的观测和组(按相似值分组)
R数据框架中的观测和组(按相似值分组)
提问于 2016-06-16 07:05:14
数据框架由变量Date、Type和Total组成,其中Type为Buy或Sell。
我们如何对观测进行分组,使只有同一Type的相邻观测被聚在一起,然后将每一组中所有观测的Total之和。换句话说,我们一直将下一个观察添加到当前组,直到Type的值发生变化。
例如,在下面的数据框架中,组如下所示
- Obs
1&2 - Obs
3&4 - Obs
5&6 7,8和9
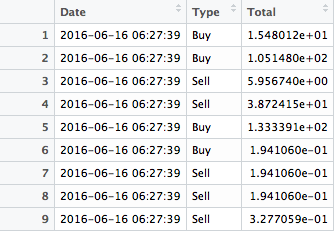
可复制的数据,谢谢@bgoldst:
df1 <- data.frame(Date=rep(as.POSIXct('2016-06-16 06:27:39'),9L),
Type=c('Buy','Buy','Sell','Sell','Buy','Buy','Sell','Sell','Sell'),
Total=c(1.548012e+01,1.051480e+02,5.956740e+00,3.872415e+01,1.333391e+02,1.941060e-01,1.941060e-01,1.941060e-01,3.277059e-01))回答 2
Stack Overflow用户
发布于 2016-06-16 07:22:55
下面是围绕aggregate()构建的一个稍微难看的基本R解决方案。它使用Type和cumsum()的连续元素之间的不等式比较来合成一个瞬态分组列,以区分Type的非顺序实例。
df <- data.frame(Date=rep(as.POSIXct('2016-06-16 06:27:39'),9L),Type=c('Buy','Buy','Sell','Sell','Buy','Buy','Sell','Sell','Sell'),Total=c(1.548012e+01,1.051480e+02,5.956740e+00,3.872415e+01,1.333391e+02,1.941060e-01,1.941060e-01,1.941060e-01,3.277059e-01));
aggregate(Total~Date+Type+TypeSeq,transform(df,TypeSeq=c(0L,cumsum(Type[-1L]!=Type[-nrow(df)]))),sum)[-3L];
## Date Type Total
## 1 2016-06-16 06:27:39 Buy 120.6281200
## 2 2016-06-16 06:27:39 Sell 44.6808900
## 3 2016-06-16 06:27:39 Buy 133.5332060
## 4 2016-06-16 06:27:39 Sell 0.7159179同样的想法是用data.table实现的:
library(data.table);
dt <- as.data.table(df);
dt[,.(Total=sum(Total)),.(Date,Type,TypeSeq=c(0L,cumsum(Type[-1L]!=Type[-nrow(dt)])))][,-3L,with=F];
## Date Type Total
## 1: 2016-06-16 06:27:39 Buy 120.6281200
## 2: 2016-06-16 06:27:39 Sell 44.6808900
## 3: 2016-06-16 06:27:39 Buy 133.5332060
## 4: 2016-06-16 06:27:39 Sell 0.7159179Stack Overflow用户
发布于 2016-06-16 07:34:22
使用data.table的简单解决方案(最新稳定版本,v1.9.6 on CRAN):
require(data.table)
# Create group id *and* aggregate in one-go using expressions in 'by'
setDT(df)[, .(total = sum(Total)), by=.(group=rleid(Type), Date)]
# group Date total
# 1: 1 2016-06-16 06:27:39 120.6281200
# 2: 2 2016-06-16 06:27:39 44.6808900
# 3: 3 2016-06-16 06:27:39 133.5332060
# 4: 4 2016-06-16 06:27:39 0.7159179页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/37852090
复制相关文章
相似问题
腾讯云开发者
