
熊猫TimeGrouper下采样的个体化起点
TL:博士
我想要分组的主题和30天的时间段,但30天的时间段不是个体化的主题。
处理这件事最好的方法是什么?
全解释
我有一个参与者的样本,他们都在不同的时间开始了一项科学研究。我想用TimeGrouper在研究的第一天之后每隔30天分割一段。
经过一些搜索后,这似乎是不可能的,因为很难为TimeGrouper指定一个起点。因此,作为代理,我可以为每个人使用第一个观察到的时间戳。
为此,我尝试按参与者ID和TimeGrouper进行分组,但30天的时间似乎是从最早的全局时间点开始计算,而不是每个参与者的最早时间点。
我知道这有点复杂,下面是一些代码:
这是一个假的dataframe,它代表了我正在使用的数据类型:
fakedf = pd.DataFrame({'participantID':['subj1', 'subj1', 'subj1', 'subj1', 'subj2', 'subj2', 'subj2', 'subj2'],
'timestamp':['2015-06-25 01:12:00', '2015-06-30 11:02:00', '2015-07-05 09:33:00', '2015-07-28 07:22:00',
'2015-07-25 01:11:00', '2015-07-31 11:02:00', '2015-08-07 09:33:00', '2015-08-10 07:22:00'], 'studystart':['2015-06-20 00:00:00', '2015-06-20 00:00:00', '2015-06-20 00:00:00', '2015-06-20 00:00:00',
'2015-07-25 00:00:00', '2015-07-25 00:00:00', '2015-07-25 00:00:00', '2015-07-25 00:00:00']})
fakedf.index = pd.to_datetime(fakedf.timestamp)以上代码应创建此数据框架:
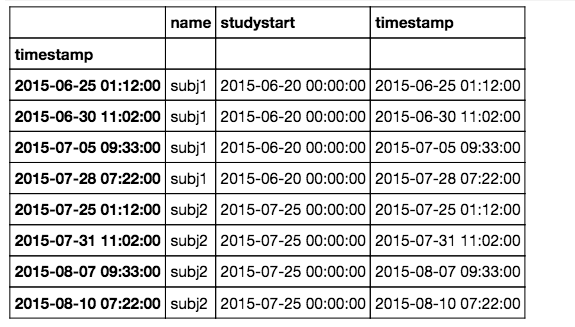
下面是我希望实际使用的代码:
fakedf.groupby(['participantID', pd.TimeGrouper(freq="30D", closed='left')]).count()这是输出:
你可以看到subj1和subj2在2015-06-25开始他们的时间分组,尽管subj2在2015-07-25之前没有真正的时间戳。
如果我能开始每隔30天的时间分组,我会很高兴的:
( a)研究开始日期,或
( b)每位参加者的第一次时间戳
我有一个低科技的解决方案,我知道这是可行的,但我希望有一个好的,优雅的TimeGrouper解决方案。
提前感谢!
回答 1
Stack Overflow用户
发布于 2016-06-21 22:16:33
要使TimeGrouper处于参与者级别,首先在'participantID'上执行groupby,然后在每个组中在TimeGrouper上执行另一个groupby。为了清晰起见,我将第二个groupby分隔成一个单独的函数。
def inner_groupby(grp, key=None):
return grp.groupby(pd.TimeGrouper(key=key, freq='30D')).count()
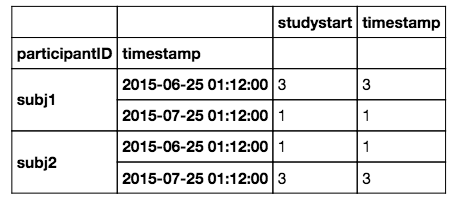
fakedf.groupby('participantID').apply(inner_groupby)由此产生的产出:
participantID studystart timestamp
participantID timestamp
subj1 2015-06-25 01:12:00 3 3 3
2015-07-25 01:12:00 1 1 1
subj2 2015-07-25 01:11:00 4 4 4您不需要为key指定TimeGrouper。默认情况下,我相信它会使用这个指数。但是,如果希望TimeGrouper位于其他列(如'studystart' )之上,则可以通过key参数传递它:
fakedf.groupby('participantID').apply(inner_groupby, key='studystart')以及key='studystart'的输出结果。
participantID timestamp
participantID studystart
subj1 2015-06-20 4 4
subj2 2015-07-25 4 4https://stackoverflow.com/questions/37954489
复制相似问题
腾讯云开发者
