
如何降低最长重复次数的复杂性
上周,我接受了亚马逊的采访。面试官问了一个问题,要找出banana中最长的重复子串,如果我们看一下字符串banana,我们会发现ana (重复2次)是一个重叠的重复字符串。我能够找到解决方案,但我的最后输出是错误的。无论如何,他说这种方法的复杂性是O(n^2),这是正确的。面试结束后,我修正了我的代码,现在它给出了正确的输出。但是我已经搜索了所有的互联网,如何降低复杂性。我找不到它。你能帮我减少复杂性或任何我可以跟随的参考来降低复杂性吗?
mystring = "banana"
temp = ""
arr = {}
for i in range(len(mystring)):
for j in range(i, len(mystring)):
temp += mystring[j]
try:
arr[temp] += 1
except:
arr[temp] = 1
temp = ""
temp = 0
finalstr = ""
for k, v in arr.iteritems():
if len(k) > 1:
if temp < v and len(finalstr) < len(k):
temp = v
finalstr = k
print finalstr回答 2
Stack Overflow用户
发布于 2016-07-08 16:09:29
该问题可以用后缀树在线性时间O(N)中求解。后缀树是包含给定文本的所有内容的树。此外,它们需要时间和空间O(N)来建造。
该树的边带有文本的子字符串标记。维基百科页面方便地为单词banana提供后缀树。
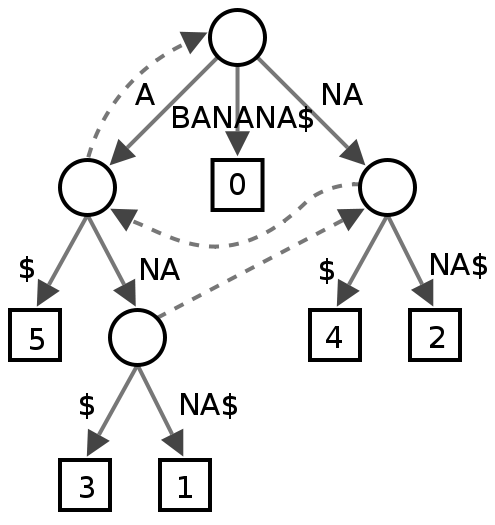
如果从根目录开始,向下读边,您将发现banana的所有可能的内容。
备注:如果你想一想,所有的长度之和都是1+2+3+...+N = N*(N-1)/2=O(N^2)!诀窍是你实际上没有用字符串来标记边缘。您将文本T作为字符串,并使用两个索引i和j标识其子字符串,因此,当您想读取边缘的标签时,您将转到索引i并读取到j。
现在的想法是,如果字符串在文本中被重复,就像ana在banana中那样,那么这个字符串就是两个不同的足够的前缀:
banana
| |
+-+-- prefix of suffix: anana
|-- prefix of suffix: ana因此,我们从后缀树的根开始,读取a,然后向左,然后读取NA,然后向右。如您所见,我们结束的节点有两个子节点:
- 左边是
$,也就是字符串的结尾,这意味着我们已经读取了ana后缀。 - 右边是
na$,这意味着我们已经读取了anana后缀。
注:这个适用于任何重复的子字符串。因此,每个重复的子字符串对应于一个分支节点。
因此,从根到最深分支节点的标签总是形成最长的重复子序列。要找到这个节点,只需对树进行一次访问即可。
要构建后缀树,最著名的算法是Ukkonnen,您可能会找到在本文中描述。算法本身是不平凡的。
我也想补充一些关于你的解决方案的评论。
首先:如果不指定要捕获的异常类型,则绝不使用,而是使用裸except:。例如,您的当前代码可能阻止用户使用Ctrl+C中断它,因为except:会捕获KeyboardInterrupt异常。在以后的面试中,请记住使用except ExceptionType和您需要的最具体的异常类型(在本例中是except KeyError:)。
其次,collections模块提供了一个Counter类,它完全是为了计数事物而编写的,因此您可以简单地重写代码如下:
from collections import Counter
length = len(mystring)
counts = Counter(mystring[i:j] for i in range(length) for j in range(i, length))
print(max(counts, key=lambda x: (counts[x] >= 2, len(x))))Stack Overflow用户
发布于 2016-07-08 16:38:43
如果我理解正确的话,你会按“b”-“ba”-.,然后“a”-“an”-.所以你正在测试从最小到最大的部分。
你有可能系统地避免最坏的情况发生吗?
例如,将字符串除以2到K,K是第一个整数,其中(len( string )/2) -1=K (K+1如果是奇数)。在出现奇数长度字符串的情况下,应该执行字符串关联。
例如,abcdedekgb连(Abcdedekgb)=10 K=4
=> 10/2 = 5 :: abcde|dekgb,
=> 10/3 =~ (3+1) :: abcd|abc|bcd|bcde|cde|cded|ded|dede|ede|edek|dek|dekg|ekg|ekgb|kgb.
=>10/4 =~ (2+1) :: ....非整数分割算法为( 10/3):len(序列)= 3+1,len(序列)=3,下一个位置为+1;
在每次迭代测试中是否存在重复,如果不是K = k+1,直到k=K。
如果单词足够大,这将很容易避免最坏的情况。
https://stackoverflow.com/questions/38270198
复制相似问题
腾讯云开发者
