
双组-到那时应用了一些功能?
双组-到那时应用了一些功能?
提问于 2016-07-26 19:01:51
我有这样的数据:
country source
0 UK Ads
1 US Seo
2 US Seo
3 China Seo
4 US Seo
5 US Seo
6 China Seo
7 US Ads对于每个国家,我想得到每个来源的比率。我做了一个关于国家和来源的小组,得到了下面的表格,其中有每个国家的每个来源的总数,但不知道如何从这里开始。
df.groupby(['country', 'source']).size()
country source
China Ads 21561
Direct 17463
Seo 37578
Germany Ads 3760
Direct 2864
Seo 6432
UK Ads 13518
Direct 11131
Seo 23801
US Ads 49901
Direct 40962
Seo 87229我在找这样的东西:
Ads SEO Direct
US .3 .1 .4
China .5 .3 .2
UK .5 .3 .6回答 3
Stack Overflow用户
回答已采纳
发布于 2016-07-26 19:11:59
您可以使用unstack将结果从长格式转换为宽格式,然后使用apply方法逐行计算比率:
import pandas as pd
df1 = df.groupby(['country', 'source']).size().unstack(level=1,fill_value = 0).apply(lambda r: r/r.sum(), axis = 1)
df1
# source Ads Seo
#country
# China 0.0 1.0
# UK 1.0 0.0
# US 0.2 0.8Stack Overflow用户
发布于 2016-07-26 19:15:12
您可以使用pd.crosstab来执行频率计数,然后使用apply来正常化:
df = pd.crosstab(df['country'], df['source']).apply(lambda r: r/r.sum(), axis=1)Stack Overflow用户
发布于 2016-07-26 19:23:11
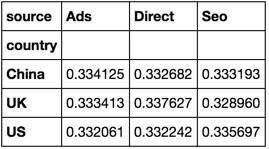
大样本集
np.random.seed([3,1415])
n = 100000
df = pd.DataFrame(
dict(country=np.random.choice(('UK', 'US', 'China'), n),
source=np.random.choice(('Ads', 'Seo', 'Direct'), n)))解决方案
size = df.groupby(['country', 'source']).size().unstack()
size.div(size.sum(1), axis=0)
计时
使用本文中的数据

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38597921
复制相关文章
相似问题
腾讯云开发者
