
R语句错误:条件的长度>1,并且只使用第一个元素
R语句错误:条件的长度>1,并且只使用第一个元素
提问于 2016-07-29 01:58:23
我有一个数据集,看起来像这样:
这就是我遇到的错误:

这是我的密码
read <- read.csv("sample.csv")
text2 <- read$text2
if(text2 == "No concern" | text2 == "No concern." | text2 == "No concerned" | text2 == "No concerns." | text2 == "No concerns") {
read$emotion <- "unknown"
read$polarity <- "neutral"
}else
{
read$emotion = emotion
read$polarity = polarity
}
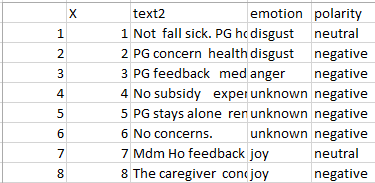
write.csv(text2, file = "test1.csv", row.names = TRUE)我实际上想用if或if等语句来改变csv文件中的情绪和极性(见附图)。我之所以想改变情绪和极性,是因为有些人是不正确的。例如,如果在text2下,它是“不关心”,“不关心”,或者“不关心”,它的情感应该是未知的,极性应该是中性的。
有人能帮忙吗?
回答 1
Stack Overflow用户
发布于 2016-07-29 22:02:55
if语句没有向量化。help("if")确实在if (cond) expr中提到了cond
长度-一个不是NA的逻辑向量。长度大于1的条件可以接受,但只使用第一个元素。如果可能,其他类型被强制为逻辑类型,忽略任何类。
您可以使用ifelse()对向量进行一些尝试:
ifelse (text2 %in% c("No concern", "No concern.", "No concerned", "No concerns.", "No concerns"),
{read$emotion <- "unknown"; read$polarity <- "neutral"},
{read$emotion <- read$emotion; read$polarity <- read$polarity}
)(由于缺少数据而无法运行)
编辑:data.table版本:
library(data.table)
read <- fread("sample.csv")
read[text2 %like% "^No concern", emotion := "unknown"]
read[text2 %like% "^No concern", polarity := "neutral"]text2 %like% "^No concern"选择以"No关注点“开头的read的所有行。只对这些行更改列emotion和polarity的内容。所有其他行都将保持原样。
注:如果业绩重要,最后两份报表可以合并成一份工作分配表。
read[text2 %like% "^No concern", c("emotion", "polarity") := list("unknown", "neutral"]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38649363
复制相关文章
相似问题
腾讯云开发者
