
如何从包含多个td嵌套标记的表中抓取
如何从包含多个td嵌套标记的表中抓取
提问于 2016-08-14 07:57:27
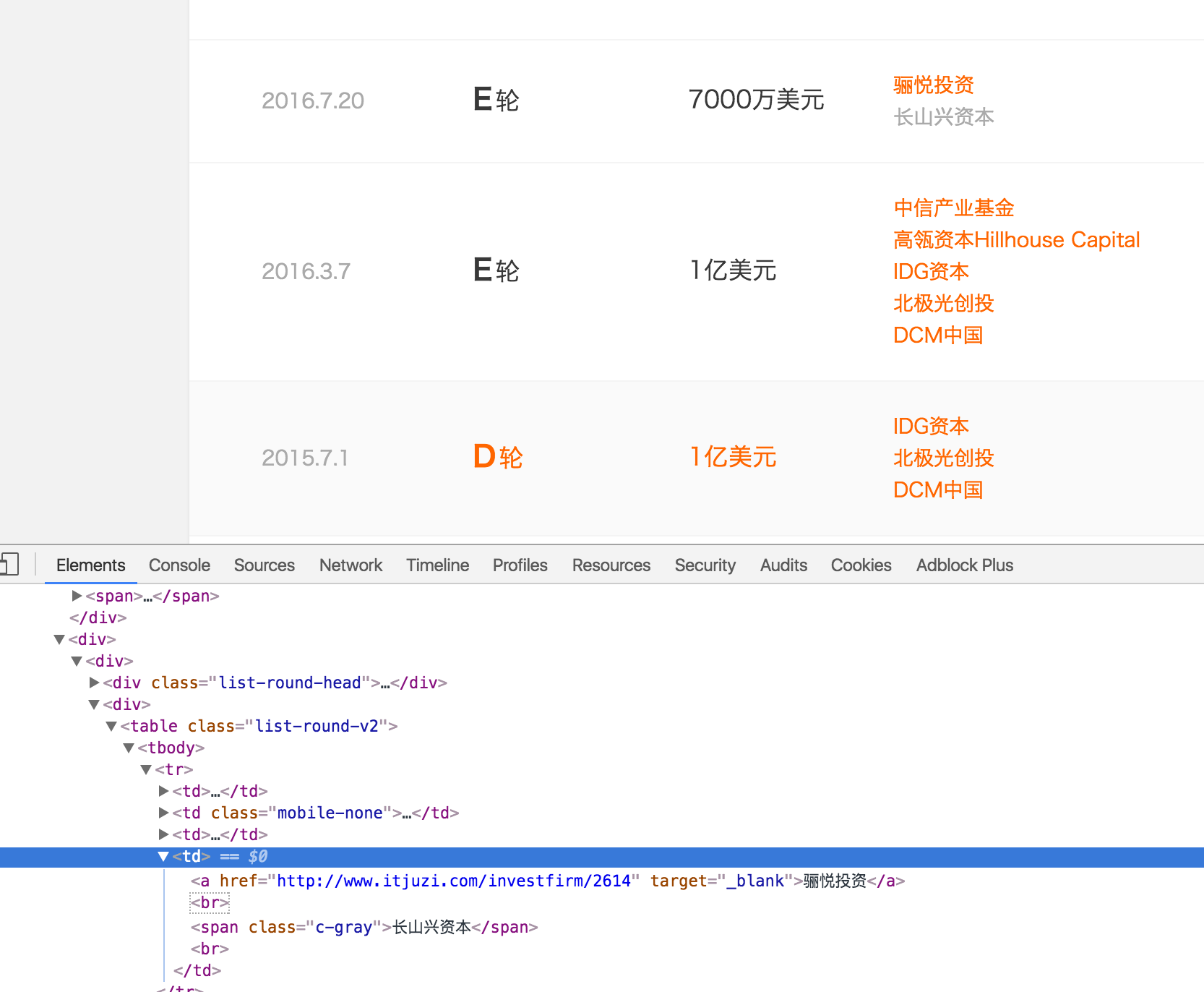
我已经从这个页面(http://www.itjuzi.com/company/934)中抓取了数据,但我想得到的是一个带有子td标记的列表,以及一个带有父td标记的列表。
守则如下:
response.xpath("//table[@class='list-round-v2']//tr/td[4]//text()").extract()我想要的结果如下:
[["骊悦投资","长山兴资本"],
["中信产业基金","高瓴资本Hillhouse Capital","IDG资本","北极光创投","DCM中国"]]
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-08-14 12:19:55
这将完成这项工作。
textlist=[]
for row in response.xpath("//table[contains(@class,'list-round-v2')]//tr"):
textlist.append(row.xpath("td[4]//text()[parent::a|parent::span]").extract())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38940281
复制相关文章
相似问题
腾讯云开发者
